SpeechmaticsEditorial Team
Oct 22, 2025 | Read time 4 min
Speechmatics Medical Model launches in Spanish
Joining French, Dutch, Finnish and English for global clinical transcription - accurate, hallucination-free, and accent-independent.
When we launched our Medical Model, we knew we were delivering next-level transcription clinicians could trust: accurate, hallucination-free, and accent-independent.
Today it arrives in Spanish, with Dutch, Finnish, and French rolling out alongside it.
TL;DR
New languages: Spanish, Dutch, Finnish, French
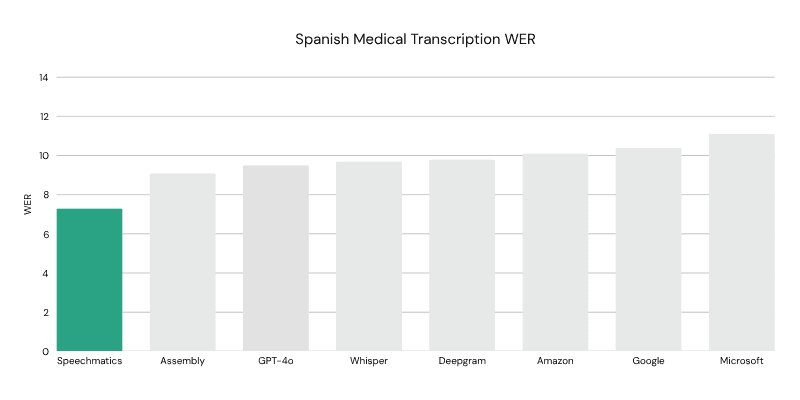
Spanish model achieves outstanding results: 7.3% WER, ahead of the next best at 9.1%
Features in every language: real-time diarization, accent-independent recognition, expanded medical vocabulary, numeric formatting, and safeguards against hallucinations
Availability: Real-time and batch & Cloud or on-prem
Why Spanish matters in healthcare
In the US, about 41.9 million people speak Spanish at home, and roughly 3.5 million Hispanic or Latino individuals work in healthcare and social assistance. Meanwhile, 35% of Hispanic adults say they prefer a Spanish-speaking provider, and adults with limited English proficiency are less likely to have a usual source of care beyond the ER. If clinical tools are optimized for English only, they fail the reality of American, and global, care. Our benchmarks for our Spanish model show:
7.3% WER on medical conversations, substantially ahead of the next best system at 9.1% – a 20% improvement in accuracy.
Consistently beats all major competitors including AssemblyAI (9.1%), GPT-4o (9.5%), Whisper (9.7%), Deepgram (9.8%), Amazon (10.1%), Google (10.4%), and Microsoft (11.1%).
The same architectural decisions that make our English model reliable and accurate carry through to Spanish. Teams can confidently expand internationally knowing transcript quality stays consistent.
Part of a wider rollout
Spanish joins French, Dutch, and Finnish as we expand our language offering across Europe and the Americas.

Key metrics for medical conversations (WER):
Spanish: 7.3% WER, ahead of the next best at 9.1%
Dutch: 4.9% WER, exceptional accuracy on clinical speech
Finnish: 6.0% WER, strong on complex morphology
French: 9.0% WER, maintains clinical reliability
Benchmarking was done using real-world conversations, and medical keyword-heavy test sets designed to push the limits of the system in a variety of real-world clinical scenarios.
"Major transformations are consistent across languages: cleaner transcripts, fewer hallucinations and better terminology handling than competitors."
Yahia Abaza, Product Manager, Speechmatics
Whether a clinic operates in Amsterdam, Helsinki, Paris, or Madrid, the quality bar remains high.
This consistency matters for organizations scaling across regions. A single API, predictable performance, uniform accuracy. Development teams can focus on building features rather than compensating for transcription drift.
Built on excellence, engineered for scale
These new languages build on our English Medical Model, which achieved an industry-leading 93% accuracy with 7.3% WER, 96% medical keyword recall, and roughly 50% fewer errors on critical medical terms compared to competitors.
The model is engineered for low latency and high throughput, handling ambient scribing, clinician dictation, and telemedicine without choking on domain terms. Real-time and batch workflows follow the same path. Deployment is flexible across cloud, private environments, and the edge.
Medical terminology coverage aligns to official standards and curated lists, updated regularly. Real-time speaker diarization separates clinician, patient, and family speaking in busy rooms. Accent-independent recognition keeps up with fast turn-taking and code-switching without forcing users to slow down.
Why reliability matters: no hallucinations, no shortcuts
General-purpose models can hallucinate. In healthcare, that is unacceptable.
Other models struggle when clinicians have accents, when patients interrupt, when background noise intrudes, or when rare terminology appears. They invent content that was never said, stumble over non-native speakers, lose track of medical terms. These are not edge cases. They are daily realities in clinical environments worldwide.
Our medical model prioritizes reliability. We use officially maintained medical standards and curated terminology lists. Evaluations focus on medical conversations with real clinical complexity. Performance stays consistent across languages and speaker conditions.
The result is transcription that reflects what actually happened in the room.
Understanding every voice
Our expansion into new languages is not a one-time release. It is an ongoing commitment.
These four languages represent the next step in our aim to understand every voice. More languages are in development. Existing models continue to improve as we refine training data, expand vocabulary coverage, and optimize for new clinical workflows.
Clinical AI moves on a foundation of accurate transcription. When the transcript is right, everything built on top works better. Ambient scribes capture the right details. Analytics surface meaningful patterns. LLM assistants generate useful summaries rather than plausible fiction.
That foundation now spans more of the world.
Getting started
Try it now: Spanish, French, Dutch, and Finnish are available in the Speechmatics Portal and via API. Both real-time and batch workflows are supported.
Bring your hardest audio: If you are building for European markets, scaling into Latin America, or supporting multilingual clinical teams, test the Medical Model with your toughest audio. We will help you measure success on your data.
Visit our healthcare transcription documentation for coverage details and integration guidance, or reach out directly about specific deployment needs.
Healthcare is global. Your transcription should be too.
FAQ
Which languages are available today?
English is available in production now. Spanish, Dutch, Finnish, and French will remain in our preview environment for a few weeks while we gather additional customer feedback.
Additional languages are in development - please contact us for roadmap details.
Do the same features work across all languages?
Yes. Real-time diarization, accent-independent recognition, medical vocabulary aligned to official standards, and hallucination resistance are consistent across all supported languages.
How does performance compare to English?
It’s tricky to compare WERs across different languages - each language has its own test sets which may vary slightly in content and difficulty.
What we have found is that these models all give excellent performance in real-world clinical environments, with Word Error Rates between 5-9%.
Can I use multiple languages in the same deployment?
Absolutely. The API supports language selection per request, so multilingual organizations can serve different regions from a single integration.
How can I get started?
Test out our English Medical model in the Portal today in real time using your voice, or with pre-transcribed files. For the other languages, you can use the Realtime Preview API to test out the other languages until the models are made available in our production environments.
Related Articles
- ProductJun 17, 2025
Speechmatics launches Medical Model for real-time clinical transcription
 SpeechmaticsEditorial team
SpeechmaticsEditorial team - Use CasesUpdated: Sep 2, 2025
AI for medical transcription: The ultimate guide to healthcare Speech Recognition
Blair RobertsonAccount Executive - Use CasesSep 26, 2025
Voice AI will dominate healthcare
 Dr Youssef AboufandiHealthcare AI Futurist
Dr Youssef AboufandiHealthcare AI Futurist

News
Stenograph and Speechmatics Announce Industry-First On-Device Integration for CATalyst VP
SpeechmaticsEditorial Team
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
Product
Speaker Focus: Fixing Voice AI for the real world
Anthony PereraProduct Marketing Manager
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
Community
From a Parked Side Project to 30 Teams Running Real Sales Calls on Speechmatics
Kyle DowFounder, Deals Machine (View1 Studio)

Use Cases
Dutch doctors spend a quarter of their day on admin. Wellcom has built the fix.
SpeechmaticsEditorial Team

General
A Practical Guide to Building Voice AI Applications With Real-Time Transcription in 2026
SpeechmaticsEditorial Team

Company
Speechmatics versus Whisper: how Adobe Premiere's on-device speech engine got rebuilt
Andrew InnesChief Architect