
Will WilliamsChief Technology Officer

Lawrence AtkinsMachine Learning Engineer

Last month, OpenAI launched its Whisper Speech to text software. An open-source model that can perform multiple tasks including ASR, language identification, voice-activity detection, and translation.
In typical OpenAI fashion, Whisper is surprisingly different from current state-of-the-art speech-to-text systems. There are three immediate key takeaways from Whisper’s approach:
Increasing the quantity of labeled data can have an instant impact: Whisper's training data contains 680,000 hours of audio. This is at least an order of magnitude larger than typical previous training regimes.
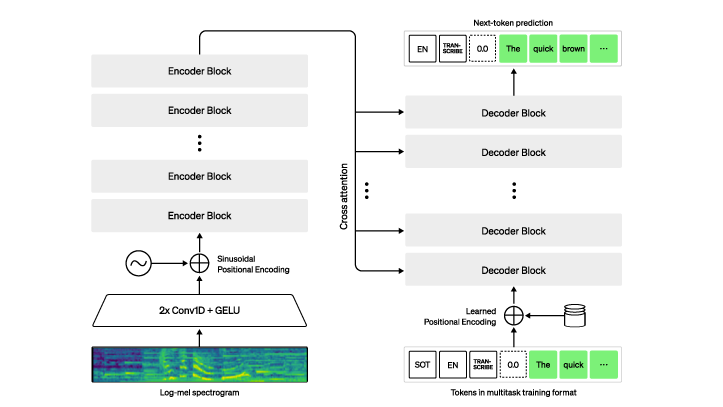
Neither model architecture nor loss needs to be complex. What matters is choosing an approach that scales well. Whisper uses a simple autoregressive encoder-decoder structure (see Figure 1), much like the original transformer paper [Vaswani et al. (2017)] [1]. The loss is simply the cross-entropy of the next word but conditioned on the audio.
If 1 & 2 are done well, then supervised learning can produce impressive systems.
This is super exciting! As is always the case when new innovations are released, there are now multiple questions that need answering. This blog aims to answer some of these and think through some of the deeper implications. We’ll develop some more takeaways from Whisper speech-to-text and point to what it means for future AI research.
OpenAI is famous for its use of scale: they were the first to formulate the neural scaling laws [2], and its GPT-series models made previous language models look very small indeed. Open AI Whisper is no different. It takes the scaling hypothesis and applies it rigorously to the domain of speech. Whisper’s authors push their setup to the limit with internet-scale labeled datasets and a simple Transformer model. Extensive internal testing at Speechmatics has shown this approach is by no means perfect, however, there is much to consider from the approach.
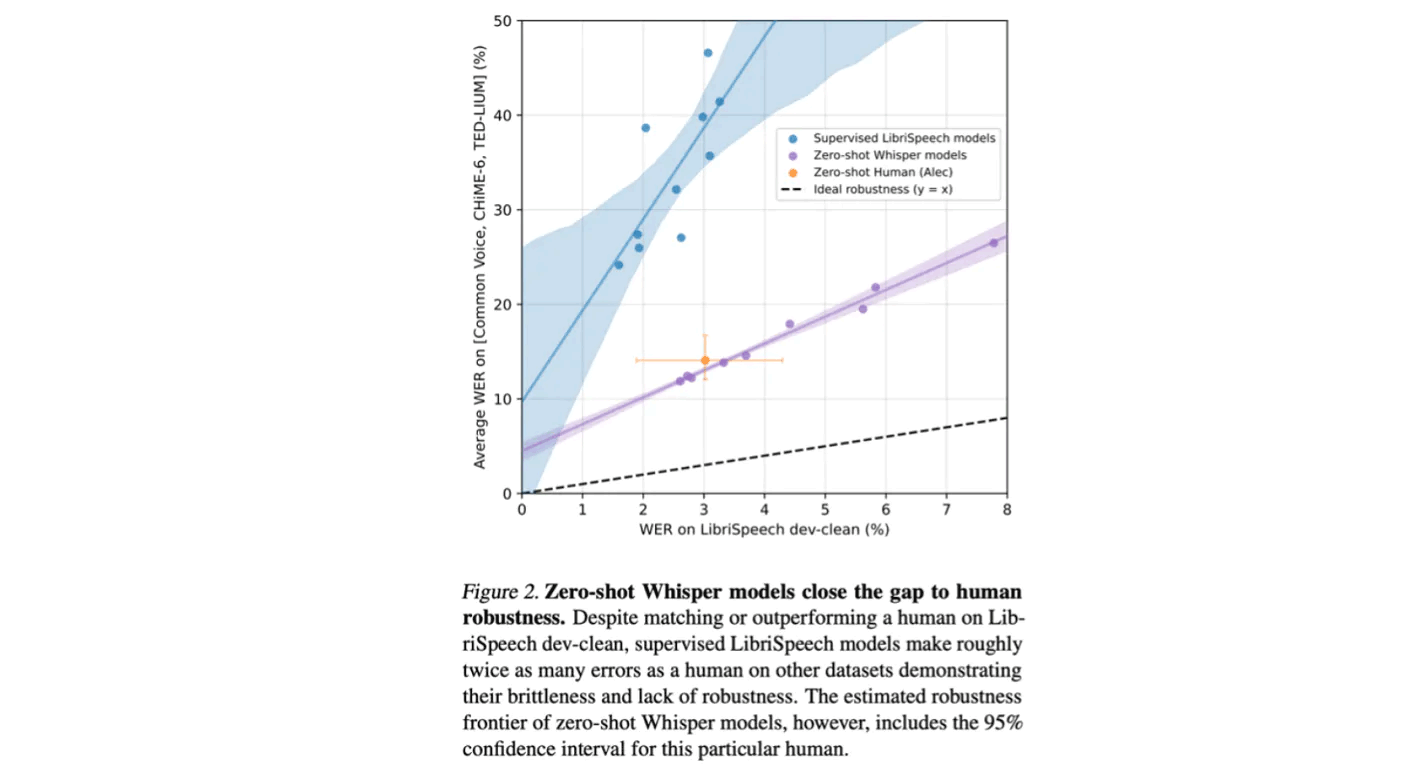
A perennial question in ASR is whether “human-level” accuracy has been achieved. In 2017 Microsoft announced [3] reaching human parity on a conversational speech recognition task, citing word error rates of 5.1% which fell in line with their human-level transcription. However, the key question always remained unasked ‘how does that result generalize to producing super-human systems across all domains’. Indeed, Professor Naomi Harte brought this exact claim into question at this year’s UK Speech conference in Edinburgh, asking whether we really are anywhere closer to general superhuman performance. This same suspicion that something isn’t quite right brought out quite strikingly in the Whisper paper [4]:
“In 2015, Deep Speech 2 (Amodei et al., 2015) reported a speech recognition system matched human-level performance when transcribing the LibriSpeech test-clean split. As part of their analysis they concluded: “Given this result, we suspect that there is little room for a generic speech system to further improve on clean read speech without further domain adaptation.” Yet seven years later the SOTA WER on LibriSpeech test-clean has dropped another 73% from their 5.3% to 1.4% (Zhang et al., 2021), far below their reported human-level error rate of 5.8%. Despite this massive and unanticipated further improvement in performance on held-out but in-distribution data, speech recognition models trained on LibriSpeech remain far above human error rates when used in other settings. What explains this gap between reportedly superhuman performance in-distribution and subhuman performance out-of-distribution?”
We suspect there are several important factors at play here. First, the authors quite rightly point the finger at a systemic failure in common evaluation protocols: the key to demonstrating generalized superhuman accuracy is to evaluate ‘out-of-distribution’. In other words, we must always evaluate data distributions from which we don’t use any training data. This is almost a given when building large-scale robust ASR systems but an important departure from common academic evaluation methodologies and clearly demonstrated to be an ongoing issue, evidenced by the gap between ‘Ideal Robustness’ and current systems in Figure 2.



![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)


