Caroline DockesMachine Learning Engineer
Nov 29, 2022 | Read time 5 min
Recognizing Rare Words: Experiments with Subword Units
Join Machine Learning Engineer, Caroline Dockes, as she explains the latest series of experiments aimed at moving speech recognition away from word-level vocabulary and towards subwords.
Language is constantly evolving. New words, new products and new expressions appear regularly in our vocabulary. We’ve explored how well speech-to-text copes with how things are in our most recent White Paper on Continuous Content. Additionally, individual domains can have very specialized vocabulary. For this and other reasons, it’s not feasible to include all possible words in an ASR system’s training data.
However, an efficient system should be able to recognize words even when it’s never seen them before. That’s easier said than done, but one step in the right direction is to move from using a word-level vocabulary to a subword-level one.
The Importance of Subwords
Using a subword vocabulary means that instead of recognizing entire words, the ASR system recognizes word pieces. These are then glued together, possibly by including word boundary markers in the system’s output. As an example, suppose someone uses the word “anthropomorphisms”. As a rarely used word, it may not have been present in the training data. A word-level model might not recognize it correctly, because the word is not in its vocabulary. It might, however, recognize a similar sounding word, or several shorter words instead.
A model trained to recognize subwords, might be able to recognize it as the concatenation of several word pieces, like anthropo+morph+isms, all of which are pieces in other English words, and so might be in its vocabulary.
In this post, we’ll describe some of the challenges and successes we’ve had when implementing this in hybrid ASR systems for English and German.
Our Choice of Tokenization Algorithm
Before we began our experiments, there were many possible subword tokenization methods to choose from, with Morfessor being a popular tool in ASR. In the end, we decided to go with Byte-Pair Encoding (BPE). BPE is a widely used algorithm, which means there are publicly available implementations that are easy to use and very fast. We also saw good results with it in early experiments on languages other than English.
Results – German
As you can see in the graph below, models trained with subwords in German perform well. A range of vocabulary sizes for the subword tokenizer achieved lower word error rates (WER) than the word-level baseline. The graph also shows, in the blue line labelled OOV (Out Of Vocabulary) recall, that the new models are able to recognize words that used to be outside of the word-level model’s vocabulary. Mostly, these are compound words, that would previously have been recognized as separate words.
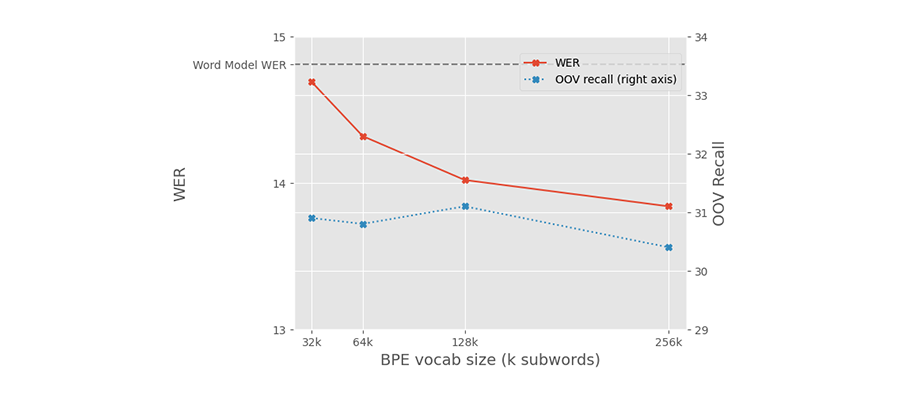
*Results shown use a subset of our training data and do not reflect the performance of the Speechmatics system.
Results – English
The results for English were... disappointing. As you can see in the graph below, all vocabulary sizes we tried resulted in higher WERs than the word-level model. Not only that, but the models trained with subword units weren’t recognizing any of the words outside of the word-level baseline vocabulary.
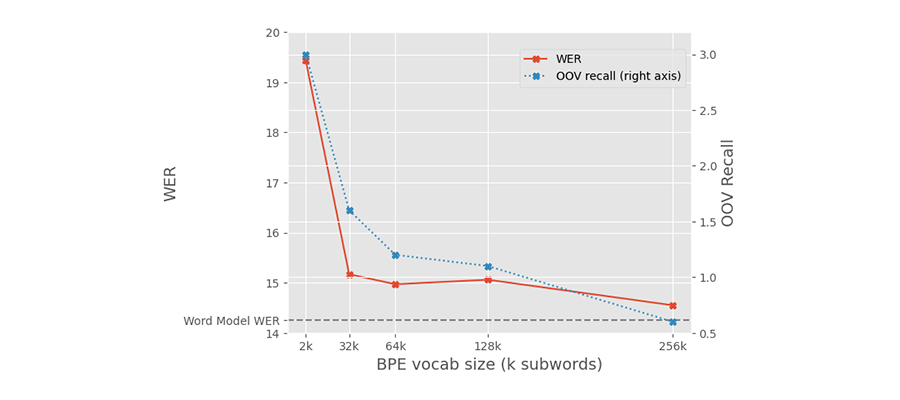
*Results shown use a subset of our training data and do not reflect the performance of the Speechmatics system.
Long-Range Dependencies
To try to explain where things went wrong in the English experiment, we need to delve a little deeper. When using subwords, a given utterance is split into more units than when using full words. Therefore, both the ngram model used for initial decoding and the neural language model for rescoring hypotheses may need to use longer contexts.
We found that increasing the length of ngrams used for decoding utterances did improve the performance of the subword models, though not by much. For example, we found that the gap in performance between the 64,000 subword model and the word-level model decreased from 5.1% to 4.6%.
A Focus on Word Delimiters
One problem with using subwords is that you have to know how to join them back into full words before returning them to the user. There are a number of ways to do this, but our approach was to add underscores to signal the start and end of each word. Returning to our earlier example, “anthropomorphisms” may be split into “_anthropo morph isms_”. Unfortunately, this means that the subword vocabulary can contain up to 4 times the same subword, with different word delimiters (_w_, _w, w_, and w).
We found that this duplication is likely harmful. Removing word delimiters entirely reduces character error rates by 2%. Unfortunately, it also removes the information needed to form whole words from the output. One possible solution would be to train a separate model to do the joining, perhaps in parallel with adding capitalization and punctuation.
The Issue with Pronunciations
Another potential explanation for the poor performance of English models trained with subwords relates to pronunciation. In English, the relationship between spelling and pronunciation is notoriously inconsistent. For instance, consider how the subword “ough” is pronounced in the words “tough”, “through”, and “dough”. In these conditions, going from phones, the output units of the acoustic model, to subwords is a difficult task.
Other papers have explored ways to take phonetic information into account when selecting what subwords to include in the vocabulary. This is an interesting avenue to explore in the future.
In Summary
The results we’ve obtained in our German experiments show that modelling language at the subword level can have large benefits in a hybrid ASR system. Unfortunately, experiments in English show that these gains may not be so easy to obtain for all languages. Our focus for the future will be on identifying more languages like German, where subwords can have a positive impact. We’ve already observed benefits for Finnish, Hungarian, Estonian, Uyghur... with more to come. Watch this space.
Caroline Dockes, Machine Learning Engineer, Speechmatics
![[alt: Medical model header asset]](https://images.ctfassets.net/yze1aysi0225/5MipUIKLJqAwbaIXNQeua8/9ea3ae3a2c022b72abbf56e26579393f/Medical_model-Header_4x3.svg)
Product
Speechmatics launches Medical Model for real-time clinical transcription
SpeechmaticsEditorial team
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
Product
Speaker Focus: Fixing Voice AI for the real world
Anthony PereraProduct Marketing Manager

News
Stenograph and Speechmatics Announce Industry-First On-Device Integration for CATalyst VP
SpeechmaticsEditorial Team
![[alt: Pattern of blue coins with "Cr", circuit symbols, and sparkles on a dark teal background, creating a crypto-themed design.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F5wtHENHGzT1GK6tG4M6USf%2Fa380442e95ea4f30ad0f5e6c42ea7ee8%2Fpricing-change-wide-carousel_2x_1.webp&w=3840&q=75)
News
A Simpler Way to Pay: Speechmatics Is Moving to Credits
SpeechmaticsEditorial Team
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
Community
From a Parked Side Project to 30 Teams Running Real Sales Calls on Speechmatics
Kyle DowFounder, Deals Machine (View1 Studio)

Use Cases
Dutch doctors spend a quarter of their day on admin. Wellcom has built the fix.
SpeechmaticsEditorial Team