
John HughesAccuracy Team Lead

In the first part of this series, we looked into what Word Error Rate (WER) is and what the flaws in the metric are. In this follow-up, we’ll be looking to see what the alternatives to WER are, as well as arguing a case for more useful approaches. To find the best approach for evaluating speech-to-text, we’ll be looking at the NER model, large language models (LLMs), few-shot learning, and chain of thought reasoning.
First up, we’ll be looking at the NER model.
Not to be confused with “Named Entity Recognition”, the NER model is an alternative way of evaluating speech-to-text. With this model, as a human goes through the transcript and fixes the mistakes, they assign a penalty that weights the severity accordingly. To calculate NER, you count the number of words (N), find the sum of edition error penalties (E) and the sum of recognition error penalties (R). This is where the name NER comes from.
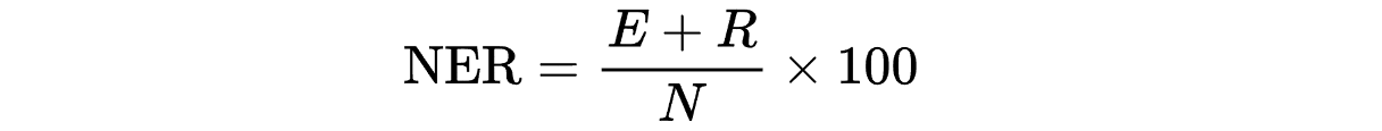
In this regard, NER is similar to WER, but the errors are not weighted evenly. Instead, they’re assigned one of three penalty levels. Here are the three penalty levels, the score associated and an example:
Minor error (0.25) – can easily read through the problem
I don’t believe in (correct text: an) executive should be able to overturn a decision.
Standard (0.5) – disrupts the flow
This is my sister. Who works at the hospital? (Correct text/punctuation: This is my sister, who works at the hospital.)
Serious (1) – drastic change in meaning
This man is a (omitted text: suspected) murderer
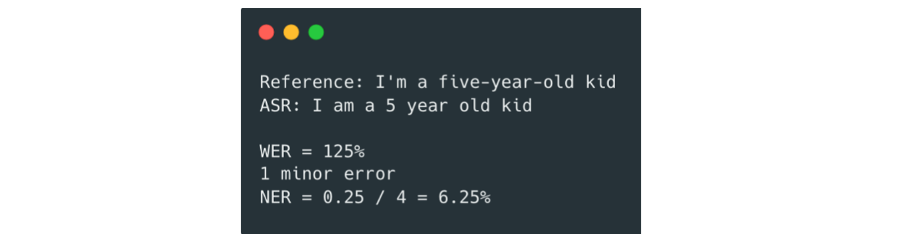
Using the same examples as in the previous blog in the series, let’s see what NER comes out with. For the first, a minor recognition error would be assigned to outputting ‘I am’ instead of ‘I’m’ since you can easily read through it. The errors from ‘five-year-old' are only because of a difference in specification, so there is no penalty assigned here. The NER equals 6.25%.
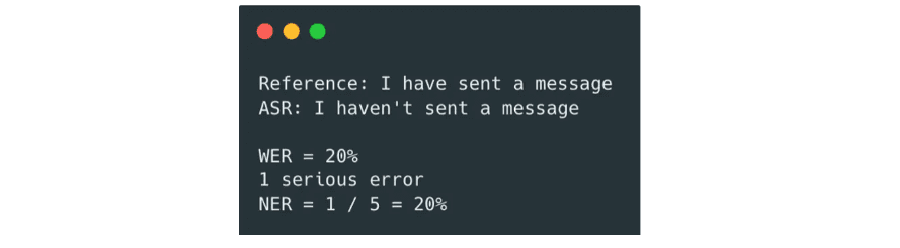
For the second, there’s a serious error assigned to incorrectly transcribing the word “have” to “haven’t”. The NER is 20%. Note the penalties assigned are subjective and different people might rate this differently.
The contrast of the two examples demonstrates the NER model is better at capturing loss of meaning and links closely with human intuition. The big problem is that NER needs a human in the loop to label the severity of errors. The severity of errors can be subjective, so it is difficult to write a set of rules to automate this. In contrast, WER follows a simple set of rules that can be fully automated. This is a large blocker in using it widely for making research decisions.
Is there a way to choose penalties for each error without a human? Before answering these questions, let’s take an aside and learn about language modelling.
A language model (LM) is trained to predict the next word, given the words that came before it. They are used in speech recognition systems, and you probably use one every day when you choose one of the three-word options your phone gives you sending texts.
Over the last few years, companies such as OpenAI, Google, and Microsoft have been scaling LMs to the extreme. Anything over 1B parameters is often referred to as a large language model (LLM). To scale LMs you must increase the amount of training data, the number of parameters in the model, and the amount of compute used to train it. There are scaling laws which predict the performance of LLMs and many different systems such as computer vision or reinforcement learning. These laws mean performance can be projected for a given compute budget.
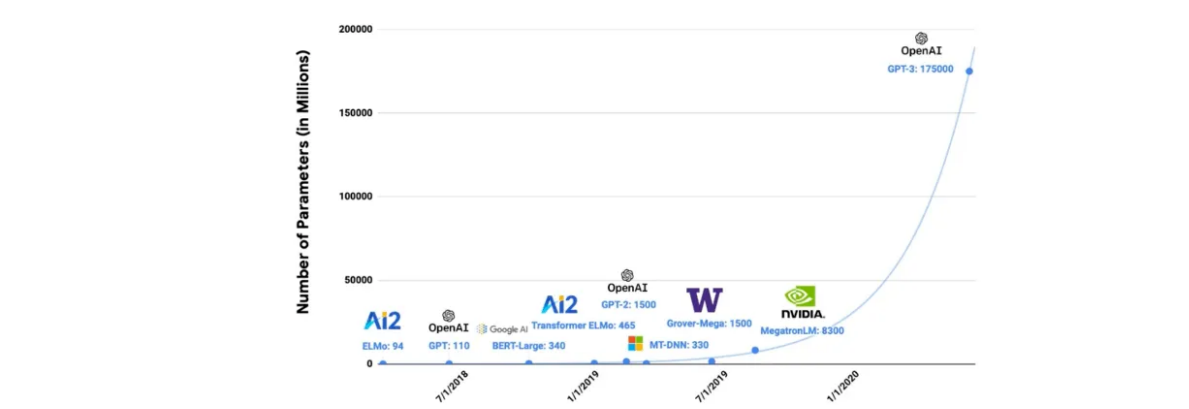
The figure below shows the number of parameters has been growing exponentially. In early 2019, GPT-2 had 1.5B parameters which OpenAI pushed to 175B in mid 2020 when training GPT-3. In June 2022, Google released PaLM (Pathways Language Model) which sits at 540B. The progress has been staggering partly due to more powerful GPUs and efficient distributed training. Interestingly, LLMs like PaLM are so large now they’re bottlenecked by the amount of text on the internet… (See lesswrong article).
The big reason the community is excited about scaling is because new capabilities emerge across a variety of tasks which would never be possible by a smaller model. Many of these capabilities are made possible by few-shot learning in which an LM is prompted with a few examples before asking it to solve the one you care about. PaLM is now better than humans at over two thirds of the 150 big bench tasks (such as reading comprehension) when they are prompted with 5 examples beforehand (5-shot learning).
To demonstrate the capabilities of scale further, take this unbelievable question answering output from PaLM which blew our minds at Speechmatics:
Michael is at that really famous museum in France looking at its most famous painting. However, the artist who made this painting just makes Michael think of his favorite cartoon character from his childhood. What was the country of origin of the thing that the cartoon character usually holds in his hand?
The most famous painting in the Louvre is the Mona Lisa. The artist who made the Mona Lisa is Leonardo da Vinci. Leonardo da Vinci is also the name of the main character in the cartoon Teenage Mutant Ninja Turtles. Leonardo da Vinci is from Italy. The thing that Leonardo da Vinci usually holds in his hand is a katana. The country of origin of the katana is Japan. The answer is “Japan”.
The astounding thing here is the cultural knowledge of our world needed to string these unrelated concepts together. This is something a LM with under 1B parameters would struggle to do no matter how much data you give it.
In April, Google trained a model called Minerva that solves high school maths problems such as knowing how to differentiate the position vector of a particle to find its speed (shown in the figure below). They achieved 50.3% accuracy on the MATH dataset which smashes the previous SOTA result of 6.9%. This is a level of quantitative reasoning that ML forecasters didn’t believe was possible for the next 3 years (see their estimates here) without significant advances in model architecture or training techniques.

The Minerva model works by fine-tuning PaLM on 118GB of data filled with LaTeX equations in web blogs and arxiv papers. At inference time, the authors provide 4 examples of solved maths problems and include the working before giving the final answer (exactly like you would in an exam). This is known as chain of thought, and they found it boosts the results of quantitative reasoning hugely, especially as the LMs get larger. In this blog, Google show that on the GSM8K dataset chain of thought reasoning increases the accuracy from 18% to 58%.
The method is illustrated in the figure below. It is a 1-shot example, and it adds the mathematical working before the answer in the prompt in order to help the model get the correct answer.
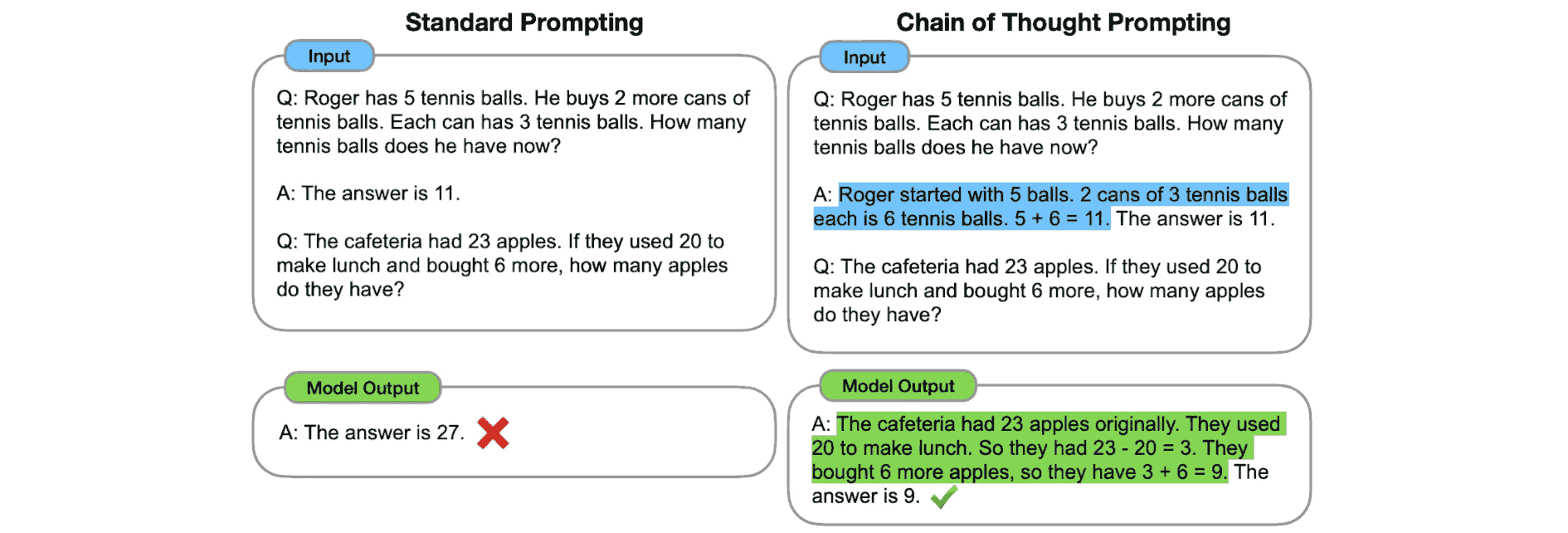
We now have all the building blocks: NER for a weighted evaluation of speech-to-text errors that aligns with human judgment; LLMs that have a human-like understanding of the intricacies of language; few-shot learning to allow the model to understand the task and structure from examples; and chain of thought reasoning to improve predictions and give a further probe into what the model is thinking.
Using the GPT-3 playground, we setup the NER task with 2-shot learning. Take a look at the chain of thought reasoning underlined in dark blue line and the severity of the error underlined in light blue. The prompt is finished with “Result:” and from that point GPT-3 starts to predict the response word by word which is highlighted in green.

Inspecting the output highlighted in green, it appears the model knows that omitting the word suspected before murder is a serious problem because it drastically changes the meaning of the sentence. You certainly wouldn’t want this incorrect transcript after a court hearing!
Using the same prompt structure, we can now run GPT3 over every reference and recognised utterance in our testset, count up the penalties associated with the predicted severities and calculate the overall NER. We now have a much more meaningful error rate that is automated.
It’s worth noting there are some alternatives that use LLMs in a slightly different way. Instead of few-shot learning and prompting, there is related work that finds the distance between the LM embedding vectors for the reference and recognized embeddings. This is a way to determine quality as utterances that have different meaning should be far apart in the embedding space. See the paper here.
We now have a novel way of automating the calculation of NER without the need for a human in the loop. All we need to do is use this 2-shot prompt for each of the utterances we want to evaluate, run the inference with GPT-3 and sum the penalties that correspond to the severity of error given in the response.
This research is still in early days and there are lots of unanswered questions. How can it deal with an utterance that has more than one error? How correlated is NER to WER? Does the chain of thought give us a new insight into where the speech-to-text models are going wrong?
Despite this, with LLMs becoming easier to access and cheaper to run, WER may become obsolete for evaluating quality in Automatic Speech Recognition (ASR). The errors will instead be closely aligned with human judgement so developers can make informed decisions when choosing vendors or making research decisions.
John Hughes, Accuracy Team Lead, Speechmatics

![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)



