
John HughesAccuracy Team Lead

Lawrence AtkinsMachine Learning Engineer

Updated March 2026
Since this article was published in March 2023, the GPT-4 family has expanded significantly. Here's what's changed:
GPT-4 Turbo (Nov 2023) — extended context to 128,000 tokens and reduced cost per token
GPT-4o (May 2024) — natively multimodal across text, audio, and image in a single model
GPT-4o mini (Jul 2024) — a smaller, faster version optimized for high-volume tasks
o1 and o3 (2024–2025) — OpenAI's reasoning-focused models, distinct from the GPT-4 line
March 14 was a huge day for the AI community. OpenAI released GPT-4, a multi-modal language model (MLLM) that has commonsense reasoning for both text and images while being able to operate with a context length of 32,000 tokens. Incredibly, GPT-4 was released less than one hour after Anthropic announced their own model, Claude. Claude is a text-only model with a context window of ~9,000 tokens.
Since GPT-4 can perceive images as well as text, it demonstrates impressive behavior such as visual question answering and image captioning. Having a longer context length (up from GPT-3’s 4,096[1]) is of major practical significance; a single prompt can cover hundreds of pages. This could be enough to contain a legal contract, a short story, or a company’s internal documents.
GPT-4 isn’t the first MLLM that has vision capabilities. In early March 2023, Microsoft released KOSMOS-1[2] which is trained on interleaved text and images. DeepMind trained a similar model, Flamingo[3], in April 2022. These models can engage in dialogue on images, image captioning, and visual question answering in a zero-shot manner, meaning they can solve problems they were not explicitly trained to solve.
This release follows several models from OpenAI that have been of interest to the ML community recently, including DALLE-2[4], Whisper[5], and ChatGPT. For those interested, we previously posted a deep-dive into Whisper and how it works.
OpenAI has not revealed information about the size, architecture, or training specifics of GPT-4*. Therefore, the purpose of this post is to present what is known and explain how models with similar capabilities (KOSMOS-1 and Flamingo) work.
We also draw conclusions from the GPT-4 Technical Report and the developer live stream. The rest of the blog is broken down as follows:
A generative language model (LM) is trained to predict the next token** in a sequence, based on some tokens that have already been provided. Through this task, the model learns to use past context to build representations of language. The training process incentivizes the model to maximize the predicted probability of the “true” token, and to minimize the probabilities of the other tokens, using cross-entropy loss. Intuitively, a good LM would generate a high probability for the token “mat” when given the context “The cat sat on the”.
GPT style models are decoder-only transformers[6] which take in a sequence of tokens (in the form of token embeddings) and generate a sequence of output tokens, one at a time. Concretely, token embeddings are converted to a sequence of features that represent the input sequence. Each layer of the model refines this representation of the input using the features learnt from the previous layer. Finally, the features of the final layer are used to generate a sequence of output tokens.
The key innovation of the transformer architecture is the use of the self-attention mechanism. Self-attention allows the model to process all tokens in the input sequence in parallel, rather than sequentially and ‘attend to’ (or share information between) different positions in the sequence.
If you’d like to understand how this works in more detail, we recommend this amazing illustrated example.

GPT-4 is trained on both text and images. Its dataset is likely similar to that of KOSMOS-1[2], which is summarized in Table 1. GPT-3 was trained on text corpora totaling roughly 300 billion tokens. The implications of DeepMind’s Chinchilla LM showed that increasing the amount of data to 1.4 trillion tokens, as well as increasing parameter count, is necessary for improving performance. We speculate that OpenAI scaled up the dataset for GPT-4 to a similar size as used by Chinchilla, or more.
| Modality | Source | Input Structure |
|---|---|---|
| Text corpora | The Pile, Common Crawl | <s>Text</s> |
| Image caption pairs | LAION-2B, LAION-400M, COYO-700M | <s><image>Image Embedding </image> </s> |
| Interleaved text and images | Collected from Common Crawl HTML | <s>Text<image>Image Embedding </image> </s> |
Table 1: The modalities, sources, and input structure of KOSMOS-1's training data.
For training, each modality must be converted to a representation in the same embedding space. In other words, we need a sequence of same-length vectors that are generated from text and images.
For text, this is straightforward since the tokens are already discretized. In KOSMOS-1, each token is assigned an embedding learned during training, the consequence being that words of similar semantic meaning become closer in the embedding space.
KOSMOS-1 deals with images using the MetaLM[7] approach. This provides a general-purpose interface supporting natural language interactions with other non-causal models. A pre-trained image encoder generates embeddings that are passed through a connector layer, which projects to the same dimension as the text embeddings. KOSMOS-1 can then handle image embeddings while predicting text tokens, as shown in Figure 1.
To do this, the model must learn the relationship between text and images. Each image consists of multiple embeddings (positional locations 7-12 in Figure 1) which are passed through the transformer. During training, only the embedding predicted after seeing all the image embeddings (e.g. x9 in Figure 1) is used to calculate the loss. When predicting this token, the transformer can still attend to all the image embeddings, thus allowing the model to learn a relationship between text and images.
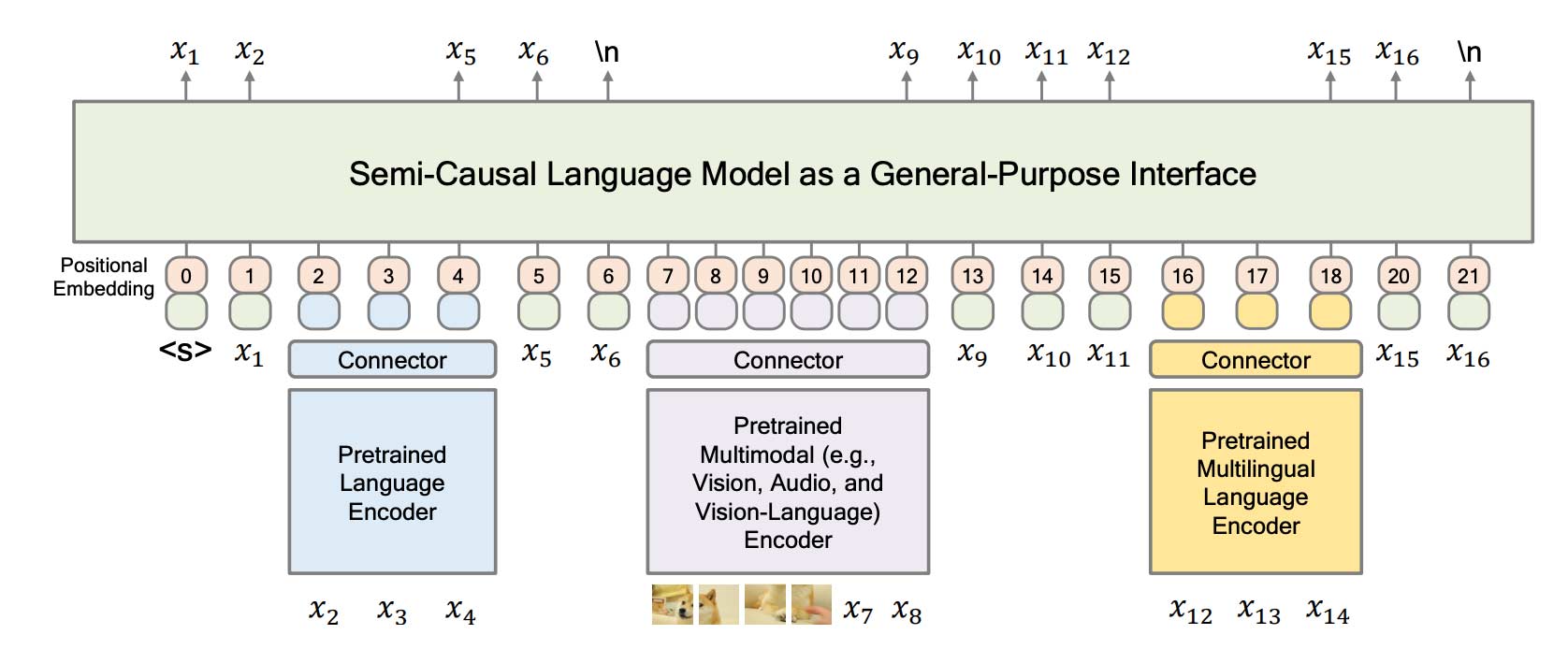
Figure 1: Diagram of MetaLM: a general-purpose interface used by KOSMOS-1 to enable visual language modelling. KOSMOS-1 only outputs text tokens, so predictions corresponding to tokens at the same position of intermediate pre-trained model embeddings are ignored during training (e.g. positions 7-11). At position 12, the multimodal input finishes and we then use token prediction x9. (image source)
The architecture used for the image encoder is a pre-trained Vision Transformer (ViT)[8] . This is common for image processing tasks. The ViT applies a series of convolutional layers to an image to generate a set of “patches”, as shown in Figure 2. These image patches are flattened and transformed into a sequence of tokens, which are processed by the transformer to produce an output embedding. The ViT is encoder-only.
The approach used to train the ViT is the Contrastive Language-Image Pre-Training (CLIP) task[9]. Roughly speaking, images and text share an embedding space, and the model is trained such that matching image-text pairs have a high cosine similarity.
During KOSMOS-1 training, the ViT parameters are frozen, except for the last layer. The exact model is CLIP ViT-L/14. GPT-4 may use this approach as well. Alternatively, it’s not unreasonable that with enough data, the image encoder can be trained from scratch.
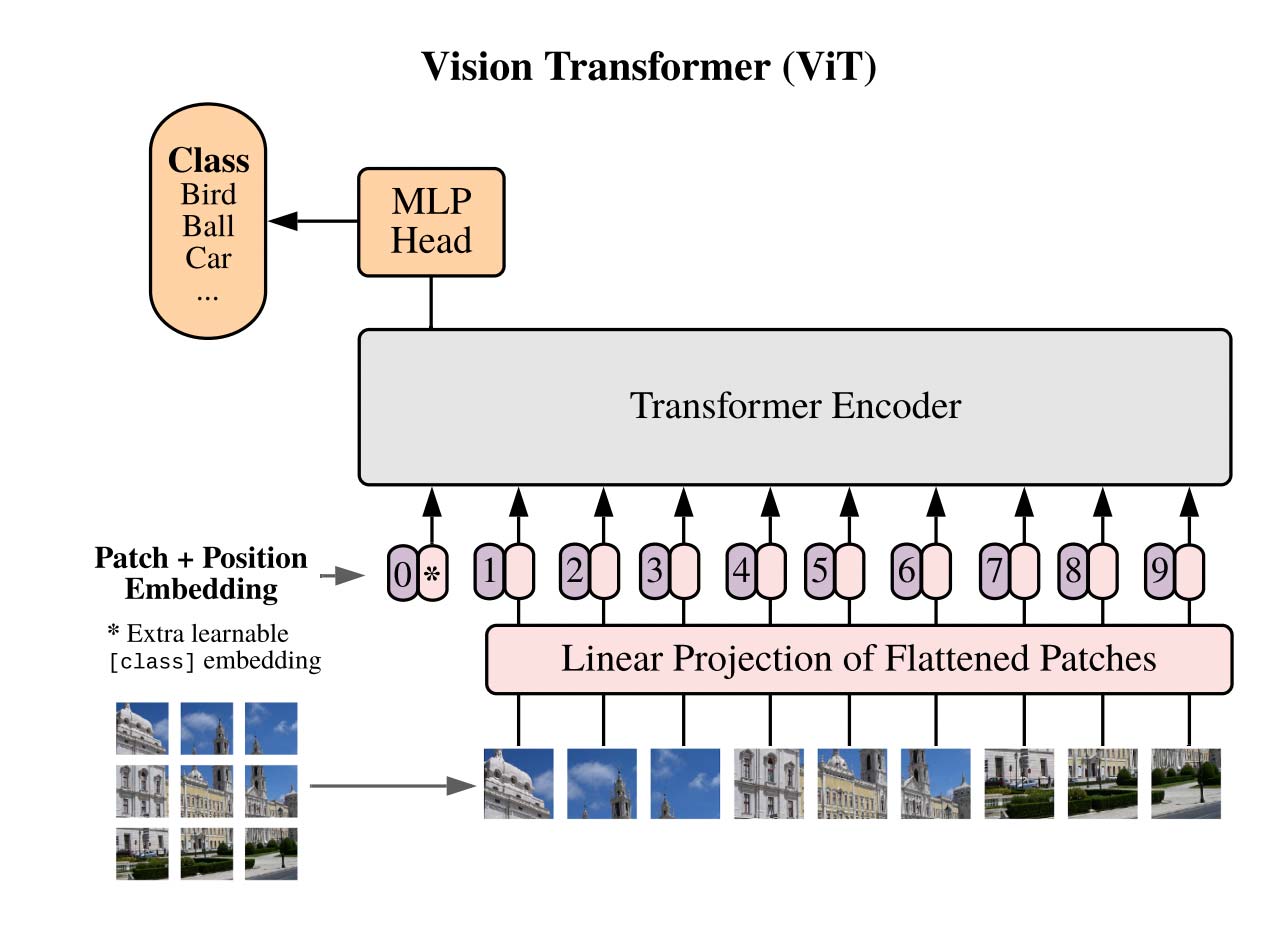
Figure 2: Overview of the Vision Transformer (ViT) architecture used as the image encoder of KOSMOS-1. The image is split into patches and processed by the transformer. (image source)
Flamingo[3] uses a different approach to multimodal language modelling. This could be a more likely architecture for GPT-4 since it was released in April 2022, and OpenAI’s GPT-4 pre-training was completed in August.
Flamingo also relies on a pre-trained image encoder, but instead uses the generated embeddings in cross-attention layers that are interleaved in a pre-trained LM (Figure 3).
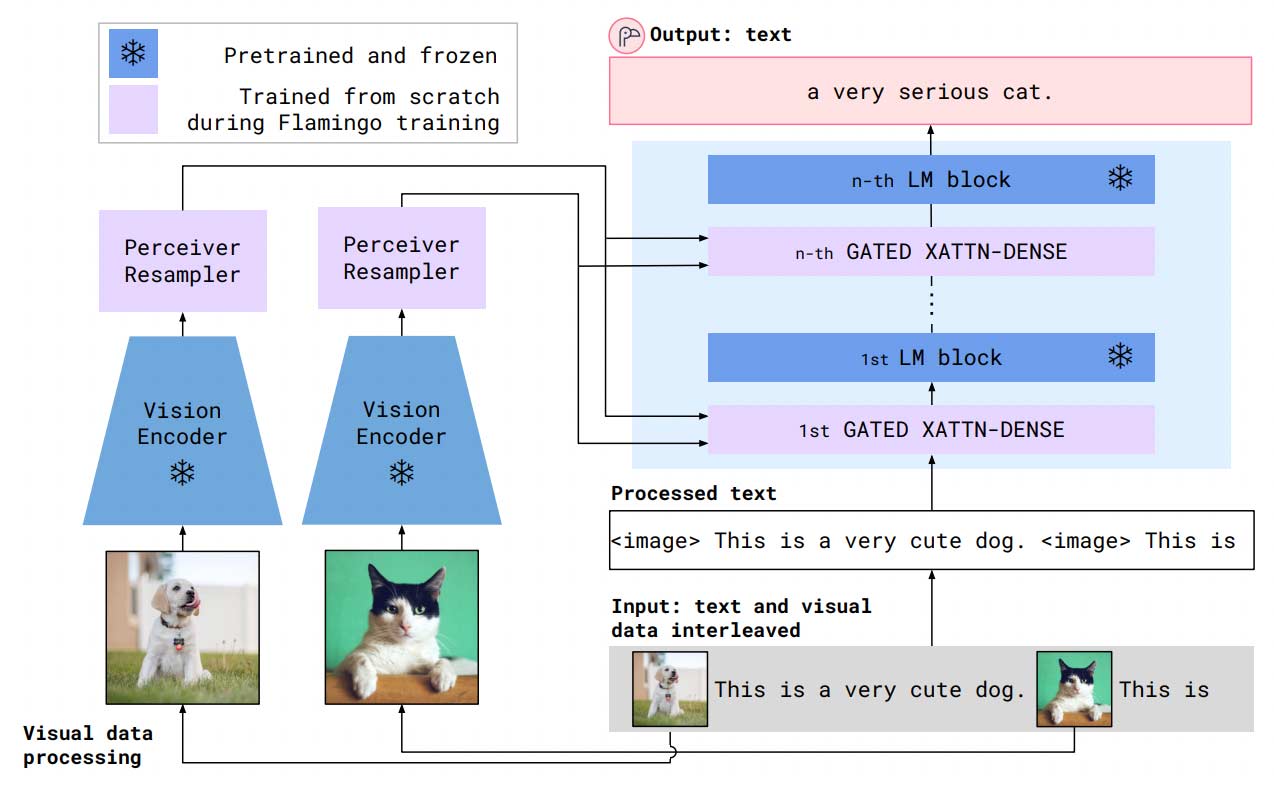
Figure 3: Flamingo’s text and image processing. Each image embedding is generated by a pre-trained image encoder. These are passed through a resampler that ensures a fixed-length representation. The embeddings are used in cross attention layers that are inserted into a pre-trained LM. (image source)
To learn more about vision language models, we recommend this HuggingFace blog.
Scaling LMs does not necessarily make them safer or more useful. This is because the next token prediction is not the same as “produce a helpful and harmless output”.
To align LMs with user intent, GPT-4 has been fine-tuned using Reinforcement Learning from Human Feedback (RLHF). OpenAI first applied this to LMs in InstructGPT[10]. The method in this paper consists of three key steps:
1) Supervised LM training on hand-labeled examples, designed to demonstrate “good” behavior.
2) Gather human-labeled preference data on example outputs from the LM. Use these to train a reward model (RM).
3) Fine-tune the LM to maximize reward.
Steps 2 and 3 are iterated upon until the finetuning yields diminishing results.
There is little doubt that massive real-world usage of ChatGPT has allowed OpenAI to gain vast amounts of preference data. It has also been confirmed that GPT-4 is the model behind Bing’s AI-powered search engine.
Anthropic’s recent paper on Constitutional AI[11] takes this further. The key idea is that human supervision comes from a set of principles – called a constitution – that we want an AI to follow. This is first used during a supervised learning phase, which has the following steps:
1) Provide the model with several prompts that are likely to produce undesirable (e.g. malicious) answers.
2) Ask the model to critique its response according to the constitution and then revise the original response.
3) Fine-tune the LM on the revised responses.
A second RL stage is then used to tune the model further. This mimics steps 2 & 3 of RLHF, except human preferences are replaced by a mixture of human and AI preferences (for more details, see the original paper). The key benefit of Constitutional AI over RLHF is that it substantially reduces the amount of human labeling required. Anthropic have confirmed that Claude was fine-tuned using this approach.
Despite this research, major issues remain. ChatGPT users will be familiar with hallucinations, wildly incorrect answers (delivered with high confidence), and the potential for offensive and/or dangerous responses when given an adversarial prompt. Indeed, examples of Bing Chat’s sometimes extremely aggressive outputs have become commonplace on social media. Nobody currently understands how to concretely align LMs with human values (or what this means in practice). See “What Next” for more discussion on AI safety.
The capabilities of GPT-4 can be broken down into two domains: text-only and text-vision tasks.
Since the performance of GPT-3.5 is so impressive, the improvements obtained by GPT-4 may not be immediately obvious to a user. However, OpenAI’s technical report[12] provides a performance comparison on a variety of academic exams, as shown in Figure 4.
The table below extends the original GPT-4 technical report comparison to include GPT-4o and GPT-4.1, giving a clearer picture of how the model family has progressed.
*GPT-4.1 uses SWE-bench Verified as its primary coding benchmark rather than HumanEval.
A few things stand out. OpenAI's o1 and o3 models, introduced in 2024–2025, use a test-time compute approach that dramatically improves performance on hard reasoning tasks Stanford — but they sit outside the GPT-4 family and are not included here. By mid-2024, top models had largely saturated MMLU o-mega, which is why newer benchmarks like SWE-bench and GPQA have become the more meaningful measures of progress.
The extent of GPT-4's visual reasoning capabilities is less clear. OpenAI has not made image inputs available for public use, and the only production environment in which they’ve been deployed is in a partnership with Be My Eyes. The technical report is vague, describing the model as having “similar capabilities as it does on text-only inputs”, and providing a few examples. Figure 5 shows one taken from the appendix.

Figure 5: An example output of GPT-4's visual reasoning with an image input. (image source)
The model is capable of both image captioning and visual question answering, like KOSMOS-1 as shown in Figure 6.

Figure 6: Demonstrations of KOSMOS-1's capabilities. (image source)
This type of capability is typically measured on a Visual Question-Answering dataset. However, publicly available data on GPT-4 and KOSMOS-1 accuracies only overlap on one dataset, making direct comparison difficult.
Yet, in the developer live stream, Greg Brockman (OpenAI President) provided some more demonstrations of GPT-4's visual reasoning. We found the most impressive example to be that GPT-4 could take a hand-drawn mockup of a website and turn it into functioning HTML, including buttons to show jokes it had created (see this Tweet). The new playground also allows the user to specify the behavior of the system, separately from providing the main prompt. For example, Greg gives the system the following instructions:
This promotes chain-of-thought reasoning[13], which helps to boost performance for certain tasks.
Since GPT-4's release, OpenAI has shipped several models that build on the same foundations described in this article:
GPT-4o is the most architecturally significant update. Where the original GPT-4 used a separate vision encoder (as described above) to process images before passing them to the language model, GPT-4o handles text, audio and images natively within a single model — removing the connector layer entirely. The RLHF alignment approach remains consistent across all versions.
| Footnotes | * The GPT-4 technical report contains no detail about "architecture (including model size), hardware, training compute, dataset construction, [or] training method" due to the "competitive landscape and the safety implications" of large LMs. ** A token can be either a word or sub-word, generated using a byte-pair encoding (BPE). BPE creates a smaller vocabulary by breaking down words into smaller sub-word units. It iteratively merges the most frequent pair of consecutive bytes in a corpus of text, gradually reducing the number of unique byte sequences until a desired vocabulary size is reached. |
| References | [1] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901. [2] Huang, Shaohan, et al. "Language Is Not All You Need: Aligning Perception with Language Models." arXiv preprint arXiv:2302.14045 (2023). [3] Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." arXiv preprint arXiv:2204.14198 (2022). [4] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 (2022). [5] Radford, Alec, et al. "Robust speech recognition via large-scale weak supervision." arXiv preprint arXiv:2212.04356 (2022). [6] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017). [7] Hao, Yaru, et al. "Language models are general-purpose interfaces." arXiv preprint arXiv:2206.06336 (2022). [8] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020). [9] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021. [10] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022). [11] Bai, Yuntao, et al. "Constitutional AI: Harmlessness from AI Feedback." arXiv preprint arXiv:2212.08073 (2022). [12] OpenAI. "GPT-4 Technical Report", OpenAI (2023) [13] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022). |
| Author | John Hughes & Lawrence Atkins |
| Acknowledgements | Edward Rees, Ellena Reid, Liam Steadman, Markus Hennerbichler |









