SpeechmaticsEditorial Team
May 26, 2026 | Read time 20 min
De-risk your voice agent: The 11 best voice agent testing platforms in 2026
Voice agents that pass in demos routinely fail in production. This guide covers the 11 best voice agent testing platforms in 2026, with the Five-Layer Testing Framework, platform deep dives, open-source alternatives, and a decision guide by maturity stage.
The world is not short of impressive Voice AI demos. Agents that ingest a single website URL in seconds and then run support calls with the expertise of a seasoned veteran. Avatars that clone any voice instantly while mirroring real-time micro-reactions. Systems that translate live voice-to-voice across languages while preserving every laugh, sigh, and cultural nuance.
The demos are striking, in part, because they are built to be.
But if you are building a voice agent, you already know how quickly the shine can disappear once real users show up. The demo environment is controlled: clean audio, short sentences, predictable intents, no overlapping speech. Production is not.
What goes wrong when voice agents meet the real world
In production, voice agents encounter packet loss that degrades audio mid-sentence. Latency spikes that cause users to talk over the agent.
Background noise from call centers, moving vehicles, and kitchens that corrupt transcription. Accented speech the ASR was never tested against. Users who interrupt, repeat themselves, change their minds mid-utterance, or simply go off-script.
Conversations long enough that context drift and hallucinations begin to compound. Function calls that succeed 95% of the time in testing but fail at 3AM during a traffic spike.
Each failure mode is distinct. Latency failures produce awkward silences that users read as confusion. Barge-in failures (where the agent keeps speaking when the user interrupts) produce the experience of talking to something that doesn’t listen.
Transcription failures cascade: a garbled turn produces the wrong intent, the wrong intent triggers the wrong function call, and the function call fails silently. By the time the transcript looks clean, the conversation has already broken.
This is the production reality that generic LLM evals are not designed to surface. An eval that checks whether a language model gave a correct text response tells you nothing about whether the agent’s audio layer will survive real telephony conditions, whether its latency profile will feel acceptable at the 95th percentile, or whether it handles barge-in correctly when a user in a noisy environment tries three times to redirect the conversation.
According to Hamming’s published voice-agent testing methodology, 42% of production issues in voice AI are voice-specific — meaning they are invisible to teams running transcript-only evaluations. That figure is vendor-authored, but the mechanism it describes is well-established: ASR errors cascade into incorrect intent detection, incorrect function selection, and degraded response quality in a way that the text layer alone cannot see.
This guide covers:
The Speechmatics Five-Layer Voice AI Testing Framework (audio validation, simulation, production observability, regression and CI, governance)
How testing requirements evolve from solo builder to enterprise deployment
A structured comparison of eleven voice agent testing platforms
Platform deep dives for Bluejay, Braintrust, Cekura, Coval, Cyara, Evalion, Hamming, Roark, SuperBryn, TestZeus, and Tuner
Open-source and DIY testing stacks
A decision tree for choosing the right platform at your maturity stage
Compliance and privacy requirements for regulated industries
Why the speech layer beneath your testing stack materially affects eval quality
How do you test a voice AI agent? The Speechmatics Five-Layer Voice AI Testing Framework
Voice agent testing is not a single category. It is five distinct disciplines that mature teams operate in parallel, and that most early-stage teams discover one at a time, usually after something breaks in production.
This section introduces the Speechmatics Five-Layer Voice AI Testing Framework: a model for thinking about voice agent QA from audio infrastructure through governance.
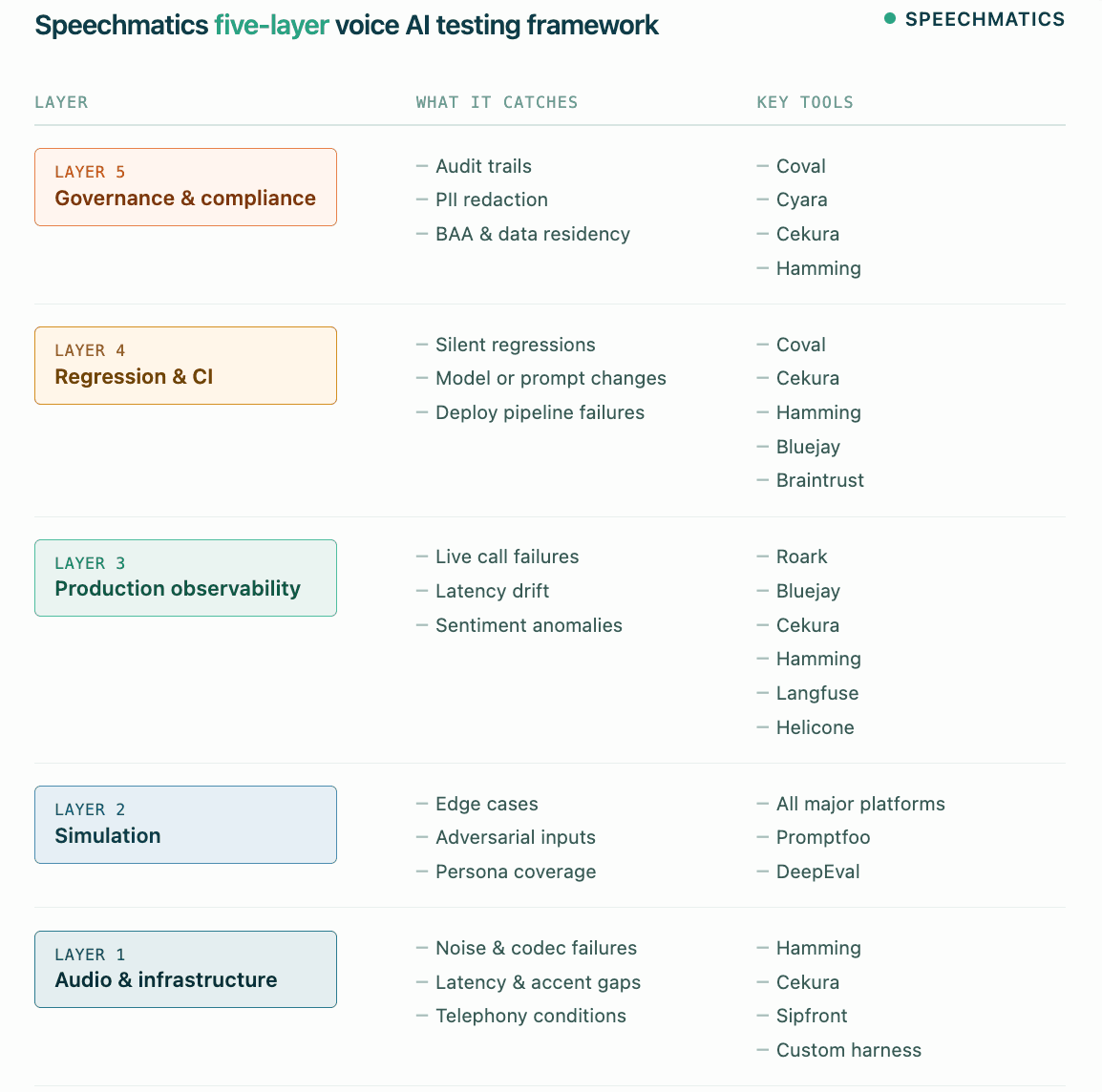
Layer 1: Audio and infrastructure validation. Testing whether the voice pipeline survives real-world acoustic and telephony conditions. This includes packet loss simulation, background noise injection, accent and dialect coverage, latency percentiles (P50, P95), and codec degradation. Most LLM-native eval stacks skip this layer entirely.
Layer 2: Simulation. Running synthetic conversations against your agent at scale, using scripted or LLM-generated personas that test happy paths, edge cases, adversarial inputs, and off-script behavior. Simulation catches failures before any real user encounters them.
Layer 3: Production observability. Monitoring live calls for latency anomalies, transcription quality, sentiment shifts, interruptions, speaker changes, and function-call failures. This is where you learn what simulation missed.
Layer 4: Regression and CI. Ensuring that a model update, a prompt change, or a new integration does not silently break behavior that was previously passing. This requires a versioned eval suite that runs in your deployment pipeline.
Layer 5: Governance and compliance. Audit trails, PII redaction, access controls, BAA coverage, and the documentation a regulated buyer or enterprise security review requires. For most early-stage teams, this layer arrives faster than expected.
The Speechmatics Five-Layer Voice AI Testing Framework: summary table
Platform comparison: voice agent testing platforms in 2026
All pricing and compliance information reflects publicly available data at research cutoff (18 May 2026). Verify directly with vendors before making procurement decisions.
Note on Cekura. Cekura was previously known as Vocera, a legacy brand associated with Cekura, not a distinct 2026 platform. Teams researching Vocera for voice agent QA should evaluate Cekura directly.
Platform deep dives
The table below summarises all eleven platforms across testing layer, best-fit stage, and compliance posture — use it as a quick-reference before reading the deep dives
Bluejay: Simulation and observability for teams shipping fast
Bluejay is a developer-oriented voice and chat agent testing platform that combines simulation, production monitoring, and continuous improvement workflows in a single interface. Founded in 2025 by Rohan Vasishth (ex-AWS Bedrock) and Faraz Siddiqi (ex-Microsoft Copilot) and backed by Y Combinator, Floodgate, and Peak XV, it positions itself as the platform for teams that want to ship fast and keep shipping.
Strengths
The ‘test + monitor + improve’ framing is more complete than platforms that stop at synthetic evals.
Production replay and scenario generation are the standout capabilities.
Limitations
Pricing opacity makes budget planning difficult.
SOC 2 Type II and HIPAA are confirmed, but BAA availability, private/VPC deployment, and audit log depth are not publicly documented — verify directly for regulated-industry procurement.
Voice-specific audio metrics are not clearly surfaced.
What users say: “Bluejay helped us go from shipping every two weeks to almost daily by letting us run complex AI Voice Agent tests with one click.” — Domenic Donato, Attuned Intelligence (vendor testimonial)
Braintrust: LLM eval infrastructure with voice audio trace support
Braintrust is a general-purpose AI observability and evaluation platform that has extended its coverage to voice, making it one of the few tools in this article that handles both text-based LLM evals and audio-native tracing in a single interface.
Unlike purpose-built voice platforms, Braintrust starts from the LLM evaluation layer and works outward, which gives it the broadest dataset management and experiment comparison capabilities in this article, at the cost of less voice-native depth than Hamming or Roark.
Strengths
Most mature eval infrastructure in this article for teams living in the LLM layer.
Dataset versioning, experiment comparison, and prompt management significantly more developed than purpose-built voice platforms.
Attaching raw audio to traces for failure investigation is a useful debugging capability.
Limitations
Not a voice-pipeline testing platform: no telephony simulation, barge-in testing, or P50/P95 latency benchmarking.
Teams needing full-stack voice QA across telephony channels will likely use Braintrust alongside a voice-native platform.
Voice-specific coverage is an extension of an LLM-first product, not the core design.
What users say: Braintrust has broader public review depth than most platforms in this article. Feedback highlights the quality of dataset and experiment management. Listed on AWS Marketplace — a signal of enterprise procurement readiness.
Cekura: Formerly Vocera, the broadest startup-tier eval stack
Cekura (formerly operating under the Vocera brand) is a broad QA platform for voice and chat agents, positioning itself around faster go-live, production monitoring, and CI/CD-integrated testing across regulated industries. Founded in San Francisco by Tarush Agarwal, Shashij Gupta, and Sidhant Kabra and backed by Y Combinator.
Strengths
Broadest evaluation coverage in the startup tier.
Explicit telephony-aware monitoring: IVR, voicemail, interruptions, latency.
Regulated-industry deployment story (in-VPC, on-prem) that few peers of similar age match.
Limitations
A significant portion of the public evidence base is Cekura-authored comparison content.
Pricing models, compliance claims, and competitive comparisons from Cekura-owned pages should be independently re-verified before relying on them for procurement decisions.
What users say: “I did a thorough bakeoff of the options out there to improve dev velocity and stability for a voice agent, and Cekura had the most intuitive platform.” — Rishi Penmetcha
Coval: Simulation-first QA with the clearest pricing in the category
Coval applies simulation-heavy QA methodology to voice and chat agents, explicitly analogizing its approach to the simulation infrastructure used in self-driving car development. Founded in 2024 by Brooke Hopkins (previously leading evaluation infrastructure at Waymo) and backed by MaC Venture Capital, General Catalyst, Y Combinator, and others through a $3.3M seed round.
Strengths
Clearest public pricing story in the category — the economics are defensible before anyone asks.
Strong compliance packaging on all tiers, not just Enterprise.
Waymo evaluation infrastructure pedigree gives technical credibility.
Limitations
Named customer logos and independent testimonials not yet clearly surfaced in public materials.
Voice-native audio benchmark detail (WER thresholds, acoustic condition coverage) less developed than Hamming’s published methodology.
What users say: Public user-review depth is still limited. The strongest credibility signals are the investor roster, the Waymo evaluation infrastructure pedigree, and unusually explicit pricing and compliance documentation.
Cyara: The enterprise CX assurance incumbent
Cyara is the category incumbent. Founded in 2006 in Melbourne, Australia, and now headquartered in Redwood City, CA, backed by over $350M in growth investment from K1 Investment Management, it arrived at AI-agent testing through two decades of enterprise CX assurance. Its Botium product and AI Trust module address the governance, compliance, and continuous-validation requirements that matter most to enterprise procurement teams. Launched agentic testing in March 2026.
Strengths
The safest enterprise shortlist inclusion — deep CX assurance lineage with 20 years of track record.
Governance and compliance tooling built for enterprise scrutiny.
Customer base includes the most compliance-scrutinised enterprise environments in the world.
Limitations
Not the lightweight tool a startup can spin up on Tuesday to test a new flow before Friday’s launch.
Procurement cycles likely to be longer.
Developer-native integrations (LiveKit, Retell, Pipecat) not confirmed in public materials.
What users say: “When it comes to speeding up the testing process, Cyara is truly transformative.” — Pavan Madireddy, TD Bank
Evalion: Three-layer testing with academic-grade benchmarking
Evalion describes itself as the ‘reliability standard for AI agents,’ combining simulation-based testing with continuous monitoring and a distinctive three-layer approach: text testing, voice testing, and hybrid AI-human review. Co-developed with enterprise clients and co-authored academic research on voice AI evaluation quality benchmarks with researchers from Oxford and Pompeu Fabra University (arXiv:2511.04133, November 2025).
Strengths
Three-layer testing architecture (text, voice, human) is genuinely differentiated.
Academic benchmarking (arXiv:2511.04133): F1 score of 0.919 vs 0.842 for Cekura and 0.728 for Coval. 42% improvement in simulation quality over the next-best platform; 86.7% accuracy in matching human judgment.
Based on 21,600 human judgments across a production-grade financial services agent.
Limitations
Pricing opacity makes self-serve adoption harder to model.
Compliance documentation less established than Coval, Hamming, or Cyara.
Earlier-stage platform; public customer and review footprint still developing.
What users say: Evalion is earlier in its public evidence journey. The clearest credibility signal is the academic co-authorship and the enterprise launch clients.
Hamming: The most developed public voice-native testing framework
Hamming is purpose-built for voice agent QA. Its public methodology is the most detailed in this category: it treats latency percentiles, WER, barge-in behavior, acoustic conditions, and telephony quality as first-class testing objects, not secondary metrics. Founded in 2024, backed by Y Combinator, building on experience scaling ML systems at Tesla and Citizen.
Strengths
Sets the highest public bar for voice-native evaluation methodology.
Clearest articulation of why ASR errors cascade into incorrect intents and degraded eval signal.
Red Team module for adversarial voice testing is a differentiator few peers have matched.
Limitations
Many compelling data points are Hamming-authored benchmarks, not independent studies.
Numeric pricing opacity makes budget planning harder.
GDPR and on-premises deployment not publicly confirmed.
What users say: “We rely on our AI agents to drive revenue, and Hamming ensures they perform without errors.” — Jordan Farnworth, Director of Engineering, Podium (vendor testimonial)
SuperBryn: Production observability with a self-improvement loop
SuperBryn positions itself as ‘Voice AI that improves itself’ — a production observability platform with an automated self-improvement loop built in. Founded in 2025 by Nikkitha Shanker and Neethu Mariam Joy in Bengaluru, backed by $1.2M in pre-seed funding led by Kalaari Capital.
Strengths
Automated improvement loop is a genuine differentiator — closes the gap from failure detection to prompt remediation without manual intervention.
Pipeline-level failure attribution (STT vs LLM vs TTS) is well-articulated and operationally useful.
Team’s 14+ years of speech AI research is a credible foundation for voice-native failure understanding.
Limitations
Very early stage ($1.2M pre-seed, 2025 founding) — introduces vendor maturity risk for enterprise procurement.
Pricing and compliance documentation not publicly available.
Limited independent review corpus.
What users say: SuperBryn’s public profile is still developing given its December 2025 founding. Published commentary emphasises production monitoring and pipeline tracing value.
TestZeus: Agentic AI testing for Salesforce Agentforce
TestZeus is an AI-powered test automation platform built specifically for Salesforce and the Salesforce Agentforce ecosystem. It occupies a distinct position in this article: where most platforms focus on audio pipelines, telephony conditions, and voice-channel latency, TestZeus is purpose-built for testing AI agents deployed within Salesforce’s enterprise workflow and CRM infrastructure.
Strengths
The clearest fit for enterprise teams running AI agents on Salesforce’s platform.
Natural language test authoring and self-healing test maintenance reduce developer burden.
Multi-turn, multi-agent Agentforce conversation testing is a capability gap most other platforms in this article do not fill.
Limitations
Not a voice-pipeline testing platform: does not test audio-layer metrics such as WER, latency percentiles, barge-in behavior, or telephony conditions.
Teams shipping voice agents on infrastructure outside the Salesforce ecosystem should treat this as a complementary tool, not a primary voice QA platform.
Public pricing, compliance documentation, and independent review depth are limited.
What users say: Its clearest credibility signals are the Salesforce-native use case positioning and Agentforce-specific testing capability. Teams evaluating TestZeus alongside general-purpose voice testing platforms should first confirm whether their agent infrastructure runs on Salesforce Agentforce.
Tuner: The observability layer every voice agent needs
Most testing tools help you catch problems before launch. Tuner is positioned for what comes after: understanding what your voice agent is actually doing in production once real users start calling it. Based in London, Tuner sits at the lighter end of the maturity spectrum — a focused, observability-first tool rather than an all-in-one testing suite — and has attracted attention in voice-AI practitioner circles as a specialist alternative to broader platforms.
Strengths
Focused observability positioning — not trying to be a full testing suite, which means teams with simulation already solved get a purpose-built production layer without platform sprawl.
Featured in practitioner-led voice-AI tooling roundups, indicating growing category awareness.
Limitations
Pricing, integration specifics, compliance posture, and detailed feature taxonomy were not publicly confirmed at research cutoff.
Limited independent practitioner reviews compared with more established players.
Observability-only scope means you will need a separate simulation or regression tool alongside it.
What users say: Tuner’s credibility at this stage rests primarily on its positioning clarity and the practitioner interest that comes with solving a concrete, specific problem.
Roark: Production-first observability and replay
Roark is production-first. Where most platforms start with simulation and extend to monitoring, Roark leads with the conviction that the most valuable signal comes from real calls. Its primary capability is capturing, analyzing, and surfacing the failures that happen in production before enough of them reach customer feedback channels. Founded in 2025 by James Zammit and Daniel Gauci, backed by Y Combinator and F-Prime Capital.
Strengths
Richest publicly surfaced prosody, emotion, and speaker behavior monitoring in this article.
Production-to-test-case replay: turning real failed calls into repeatable test cases is operationally powerful.
‘Catch the uh-oh moments before customers do’ philosophy reflects genuine production-realism.
Limitations
Consumption-based pricing with undisclosed minimum creates budget uncertainty.
Compliance documentation behind the badge surface is thinner than Coval or Hamming.
Independent practitioner commentary is limited.
What users say: The platform’s promise around production observability resonates with the market. Observable evidence is customer logos and the 10M-minutes scale claim.
Open-source and DIY voice AI testing stacks
Not every team needs a dedicated testing platform. Early-stage builders often assemble effective testing workflows from open-source tools before moving to commercial platforms.
The distinction matters: open-source tools cover Layers 2 and 4 (simulation and CI regression) reasonably well; they cover Layers 1, 3, and 5 poorly or not at all.
Before the tool-by-tool breakdown, it's worth being clear on where open-source options genuinely hold up, and where they don't.
Promptfoo. A CLI-first eval harness that runs prompt variations, compares outputs, and integrates into CI pipelines. Well-maintained, actively developed, and capable of handling multi-turn conversation evals with custom scoring functions. Strong for transcript-level regression testing. Does not simulate audio conditions.
DeepEval. A Python-native LLM testing framework with built-in metrics for hallucination, answer relevance, faithfulness, and conversational coherence. Works well alongside Langfuse or Helicone for trace capture. Operates on the text layer.
Langfuse. LLM observability tool that captures traces, logs inputs and outputs, and surfaces latency and cost data. Production observability for the text layer — useful context, not voice-native monitoring.
Helicone. Similar to Langfuse: LLM cost and latency monitoring. Solid free tier for early-stage teams.
Braintrust. Broader eval platform with dataset management, trace logging, and experiment versioning. Can be configured for voice agent evals with custom scoring, but is not purpose-built for audio behavior.
Sipfront. SIP-native performance and functional testing tool aimed at telephony infrastructure. If your voice agent runs over SIP and you need to stress-test call handling, codec behavior, and network degradation, Sipfront addresses a gap that most other open-source tools leave open.
The core limitation of the open-source stack is not functionality at the text layer — it is the absence of audio. A perfectly clean transcript can still represent a call that felt broken: the pause before the agent responded was 4 seconds at P95. The agent kept speaking when the user tried to interrupt. The background noise degraded ASR accuracy by 15 percentage points. None of this appears in a transcript eval.
Which voice agent testing platform should you choose?
The right platform depends on two axes: where you are in your deployment maturity, and what type of failure you are most exposed to right now.
If you are pre-launch and building fast: Start with Coval (Starter) or Cekura (Developer) for structured simulation and CI integration. Both have free trials, self-serve onboarding, and pricing clarity you need to decide whether to stay. Hamming is a strong alternative if voice-native audio testing (WER, barge-in, noise simulation) is already on your radar.
If you are post-launch and seeing unexplained production failures: Roark is the strongest production-observability choice: it captures what happened in real calls and converts failures into test cases. Bluejay’s monitoring layer is an alternative if you also want the simulation and improvement loop in a single platform.
If you are scaling and need CI coverage across multiple models or prompt versions: Coval (Growth) or Hamming are the right shortlists. Both combine pre-launch simulation with regression coverage in CI pipelines. Coval’s advantage is pricing transparency; Hamming’s advantage is voice-native framework depth.
If you are in healthcare, financial services, or another regulated industry: Coval (Enterprise) offers the most comprehensive public compliance posture: SOC 2 Type II, HIPAA, GDPR, BAA, private/VPC deployment, data residency, and audit logs. Hamming (HIPAA, BAA, SOC 2 Type II) and Cekura (SOC 2, HIPAA, GDPR, in-VPC) are strong second options.
If you are an enterprise contact center already running CX assurance workflows: Cyara’s depth in governance, compliance, and the complexity of large-scale CX environments is unmatched in this article.
If your priority is academic-grade evaluation quality and hybrid human review: Evalion’s three-layer approach and published benchmark data make it the differentiated choice for teams where eval accuracy itself is a business requirement.
Where current voice agent testing platforms fall short
No platform in this article covers all five layers equally well. That is not a criticism — the category is still maturing — but it is a practical reality for teams building serious production systems.
Audio infrastructure testing at scale is underserved. Most platforms simulate conversation quality, but telephony-layer stress testing — packet loss, codec degradation, network jitter under your actual traffic profile — is not a prominent feature of the startup cohort. Sipfront fills part of this gap for SIP-native infrastructure. For modern cloud voice stacks, custom harnesses are often still necessary.
Independent benchmarking is nearly absent. Almost every metric cited in this article — 42% of failures are voice-specific, 4M calls tested, 10M minutes processed — is vendor-authored. The Evalion/Oxford/Pompeu Fabra paper (arXiv:2511.04133) is the only independent cross-platform evaluation published at time of writing, and it covers just three platforms. The category needs Hugging Face-style public leaderboards for voice agent eval quality. None exist yet.
PCI compliance is largely uncharted. Several platforms work with teams building payment-taking voice agents but have not published PCI DSS certifications. Until that changes, teams in payment flows need to verify compliance posture directly — or rely on segmentation and synthetic test data to avoid real card numbers entering the pipeline at all.
Most platforms measure what the agent did, not what the user experienced. Task completion rates, abandonment points, caller sentiment trends, and resolution quality are underserved relative to the volume of latency and WER metrics these tools produce. The gap between ‘the agent completed the function call’ and ‘the user felt heard and resolved’ is real, and most testing frameworks measure the former.
Pricing opacity makes vendor switching expensive to model. Seven of eleven platforms in this article have no published pricing. That concentrates commercial power with vendors’ sales teams rather than with technical buyers. The market will improve as it matures.
Testing voice agents in regulated industries
Regulated industries don't just raise the stakes for voice agent performance. They raise the stakes for how you test it. If your agent handles patient calls, financial data, or payment flows, the testing and observability infrastructure around it falls within the same compliance scope as the product itself.
The rules below aren't edge cases; they apply to any team shipping voice agents into healthcare, financial services, or contact centre environments.
Healthcare (HIPAA). The U.S. Department of Health and Human Services defines protected health information (PHI) as individually identifiable health information held or transmitted by a covered entity or business associate, in any form or medium. That scope includes audio recordings and metadata associated with care and identity, not just transcript text. Any testing platform that ingests or replays real healthcare call audio is therefore in scope for PHI controls. Verified options with HIPAA and BAA coverage: Coval (HIPAA across all plans, BAA on Enterprise, private/VPC) and Hamming (HIPAA, BAA, SOC 2 Type II).
Legal and financial services (GDPR, data minimization). GDPR requires a lawful basis, purpose limitation, and data minimization for personal data. Identifiable voice recordings and transcripts can qualify as personal data. Two testing patterns have different risk profiles: synthetic simulation (lower risk, no real identifiers) versus production replay (higher value but sharply raises access controls, retention limits, masking, auditability, and deployment requirements). The procurement question is not ‘simulation or replay?’, it is ‘what controls exist when you do either?’
Payment workflows (PCI DSS). Voice agents handling payment flows should assume testing infrastructure is within PCI scope unless robust segmentation, masking, and retention controls are in place. Explicit PCI DSS certifications are scarce across this platform set; teams should verify compliance posture directly with vendors before including any payment-flow call recordings in their testing pipelines.
Contact centers (consent, logging, TCPA). Voice agent testing frequently involves outbound calls, voicemail behavior, recording, and replay, all of which sit in a regulatory environment policed by the FCC and TCPA. The compliance question for any observability or replay system: can you prove what happened, who accessed it, what was masked, and how long it was retained? Strongest public audit-log posture in this article: Coval. Cekura also explicitly references audit trails.
Regulated-industry compliance snapshot
‘Not confirmed’ reflects publicly available documentation at time of publication; it does not indicate the absence of a control. Teams should request current trust documentation directly from each vendor.
Final thoughts
Voice agents are not hard to demo. They are hard to ship.
The gap between a compelling demo and a reliable production system is where voice agent testing platforms earn their justification. The audio layer — transcription accuracy, latency behavior, barge-in handling, acoustic conditions, is where most production failures originate, and where most transcript-only eval stacks remain blind.
The platforms in this article address different parts of that problem. Simulation-first tools catch failures before they reach users. Observability-first tools catch what simulation missed. Compliance-oriented platforms provide the auditability that regulated industries and enterprise procurement require. No single platform covers the entire stack equally well, which is why the most mature teams typically run more than one.
The right question is not ‘which testing platform is best?’ It is ‘which failures am I most exposed to right now, and which platform is best equipped to surface them?’ Start there, and expand the stack as your deployment matures.
For teams building on Speechmatics as the speech layer beneath their voice agent, the additional note is this: a cleaner transcript produces a more reliable eval signal. The accuracy of what gets fed into the testing pipeline matters as much as the platform that processes it.
Frequently asked questions
What is voice AI agent testing?
Voice AI agent testing is the practice of validating that a voice agent performs correctly and reliably before and after production deployment. It covers pre-launch simulation, production observability, regression testing for model updates, and compliance verification for regulated industries.
How is voice AI testing different from chatbot testing?
Chatbot testing evaluates text input and output. Voice AI testing evaluates the full audio pipeline: transcription accuracy, latency, barge-in handling, background noise tolerance, telephony quality, and speaker behavior. Failures in voice agents frequently occur at the audio layer in ways that produce a clean-looking transcript — which transcript-only eval stacks miss entirely.
What is the best voice agent testing platform for startups?
For pre-launch or early post-launch stages, Coval and Cekura offer the clearest entry points: both have free trials, self-serve pricing, and CI/CD integration. Hamming is the strongest choice for teams that need voice-native audio testing from day one. Roark suits teams with live call volume who want to convert production failures into repeatable test cases.
What is the best platform for enterprise contact centers?
Cyara is the established enterprise choice: over $350M in funding, 20 years in CX assurance, and customers including Microsoft, AT&T, and Liberty Mutual. For regulated environments that also need self-serve developer access and explicit compliance packaging, Coval Enterprise offers the strongest public compliance posture: SOC 2 Type II, HIPAA, GDPR, BAA, private/VPC, and audit logs.
What is the difference between Coval and Roark?
Coval leads with simulation and pre-launch evaluation, with the strongest published pricing and compliance documentation in the startup tier. Roark leads with production observability and the richest public prosody, emotion, and speaker monitoring framework. Teams choosing between them are often choosing between building confidence before launch (Coval) and catching what breaks in real calls (Roark). Many scaling teams use both.
Can I test a voice agent without code?
Bluejay and Cekura both offer scenario builders in their interfaces that reduce the code required for simulation setup. Full pipeline testing, including CI integration, production replay, and custom scoring functions, requires developer access and configuration regardless of platform.
What are the best open-source tools for voice agent testing?
Promptfoo and DeepEval are the strongest open-source options for transcript-level simulation and CI regression. Langfuse and Helicone cover LLM observability at the text layer. Sipfront addresses SIP and telephony layer testing. None of these provide voice-native audio simulation or production observability at the audio layer.
How do you test voice AI agents for HIPAA or GDPR compliance?
For HIPAA, any platform that ingests real call audio or transcripts containing PHI requires a BAA, private/VPC deployment, audit logs, and access controls. Verified options with HIPAA and BAA coverage: Coval and Hamming. For GDPR, synthetic simulation datasets reduce risk by avoiding real identifiers; production replay sharply raises data minimization and purpose-limitation requirements.
How much does voice agent testing actually cost?
The only platforms with fully published pricing are Coval and Cekura. Coval Starter: $100/month. Growth: $500/month. Enterprise from $4,500/month. Cekura Developer: $30/month for 750 credits; voice testing at 5 credits/minute works out to roughly $0.20 per one-minute simulated call. All other platforms — Bluejay, Cyara, Hamming, Roark, Evalion, SuperBryn, Tuner, TestZeus, and Braintrust at enterprise — are sales-led or have unpublished pricing.
Do I actually need a dedicated voice agent testing platform?
Not always. Three scenarios where the answer is probably not yet: (1) You are pre-product-market-fit with fewer than a few hundred calls per week — a transcript-level eval harness like Promptfoo or DeepEval is sufficient. (2) Your agent runs over a purely text-based API with no ASR/TTS layer. (3) You are trying to implement compliance-grade governance before you have any live users — that sequence is usually backwards. The right order is simulation pre-launch, observability once you have live traffic, and compliance tooling when deal size or regulation demands it.
What are the most common voice agent testing mistakes?
Seven patterns that recur across production teams: (1) Testing only the transcript layer, missing the 42% of failures that occur at the audio layer. (2) Optimising for P50 latency while ignoring P95 tail latency, which drives abandonment. (3) Simulating only happy paths and missing adversarial inputs. (4) Not testing under real acoustic conditions — background noise and codec artifacts can degrade ASR by 5–15 percentage points. (5) Treating go-live as a one-time event rather than running continuous regression tests. (6) Missing the compliance scope — HIPAA, GDPR, TCPA — until after an incident. (7) Conflating passing tests with satisfied users, and underinvesting in production observability.
Related Articles
- ProductApr 1, 2026
Speechmatics and Cekura bring real-world STT testing to voice agent pipelines
 SpeechmaticsEditorial Team
SpeechmaticsEditorial Team - TechnicalMar 31, 2026
Speech-to-text in production: what 36 years of hard lessons taught me
 Dr Tony RobinsonFounder
Dr Tony RobinsonFounder - TechnicalUpdated: Sep 21, 2025
The Problem with Word Error Rate (WER)
 John HughesAccuracy Team Lead
John HughesAccuracy Team Lead
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
Product
Speaker Focus: Fixing Voice AI for the real world
Anthony PereraProduct Marketing Manager

News
Stenograph and Speechmatics Announce Industry-First On-Device Integration for CATalyst VP
SpeechmaticsEditorial Team
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
Community
From a Parked Side Project to 30 Teams Running Real Sales Calls on Speechmatics
Kyle DowFounder, Deals Machine (View1 Studio)
![[alt: Pattern of blue coins with "Cr", circuit symbols, and sparkles on a dark teal background, creating a crypto-themed design.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F5wtHENHGzT1GK6tG4M6USf%2Fa380442e95ea4f30ad0f5e6c42ea7ee8%2Fpricing-change-wide-carousel_2x_1.webp&w=3840&q=75)
News
A Simpler Way to Pay: Speechmatics Is Moving to Credits
SpeechmaticsEditorial Team

Use Cases
Dutch doctors spend a quarter of their day on admin. Wellcom has built the fix.
SpeechmaticsEditorial Team

General
A Practical Guide to Building Voice AI Applications With Real-Time Transcription in 2026
SpeechmaticsEditorial Team