SpeechmaticsEditorial Team
May 7, 2026 | Read time 12 min
Alphanumeric speech recognition: why voice assistants mangle SKUs (and how to fix it)
A guide for voice AI engineers, ecommerce platforms and warehouse teams on SKU recognition accuracy voice assistant deployments depend on: why speech recognition systems produce transcription errors on product codes, what to measure when error rates matter, and the fixes that move the needle on order picking, voice ordering and customer-facing voice AI.
Why speech recognition fails on product codes
Modern ASR leans on statistics. Speech recognition systems and voice AI systems trained on conversational training data hit high accuracy on natural speech because the language-model prior is strong: “for two” beats “for too” because the surrounding context makes it more probable. A SKU like BRN-4421-XL has no such prior.
Every character is roughly equally probable, so the model is guessing where it would normally be predicting. Letter and digit names are also among the most acoustically confusable tokens in English: P vs B, M vs N, O vs zero. This is why the same architectures that produce clean meeting transcripts can still mis-handle a single spoken code.
The clearest public illustration is the SNuC corpus from the University of Sheffield. A baseline ASR system reached 96.6% word-level accuracy on partner data but only 77% full-identifier exact match. After identifier-specific adaptation, accuracy rose to 91.7%. Near-97% word accuracy still left almost one in four identifiers wrong, which is the single most useful framing in this whole topic. Most SKU recognition errors fall into a small set of predictable patterns, and knowing them is the first step toward fixing them. Drawn from the spoken-identifier literature, the worst offenders look like this:
Product names and brand terms are acoustically ambiguous
Brand names are not natural language either. Invented names do not appear in standard training data, so the model substitutes the nearest real word. ASR systems generalize poorly on accented speech, with accuracy typically dropping by around 15% on strong regional accents. “XL” and “XS” sound alike at telephone bandwidth. Color names get confused across diverse accents. When customers stack modifiers, such as “large navy slim-fit”, the model can capture every word and still bind the wrong attribute to the wrong product.This is the rare-entity problem, and the lever that moves the needle is better context applied at the point of recognition. Speechmatics’ Custom Dictionary is built for exactly this kind of problem: domain-specific words, names, acronyms, branded terms and terms outside standard English phonetics.
Single-character errors and their commercial impact
These confusions might look academic on a slide. They cost real money once they meet a real workflow. In a 10-character SKU, one misrecognized character means the wrong product, and here is what that looks like once it leaves the recognizer:
The downstream cost is measurable. In one retail distribution center study, 7% of purchase orders had a fulfillment error and the correctable rework alone cost 1 to 4 percent of the DC’s operating budget.
Order picking already accounts for 50% to 70% of warehousing costs, so transcription errors at the identifier layer have outsized operational impact.
In voice ordering, the impact is trust: PwC research found nearly half of consumers who would not shop via voice cited lack of trust in the device to get orders right, and recent quick-commerce work confirms order accuracy is the strongest driver of customer satisfaction.
Customers tolerate one mistake. They do not stay around for a second.The same dynamic applies to medical transcription, where alphanumeric IDs and dosages carry safety consequences, and to contact-center work, where one wrong account number ends a session and burns trust with the caller.
Why exact match beats word error rate (WER)
WER is a token-level average. Identifier capture is binary: every character has to be right, or the order, lookup or pick fails. For SKU recognition accuracy, the only metric that survives contact with the business is sequence-level exact match.
This is why headline accuracy numbers should be treated carefully. If you want the longer version, read Speechmatics’ guide to assessing speech-to-text accuracy, or the deeper piece on the future of word error rate.
Voice-assisted order picking in warehouses
Nowhere is alphanumeric speech recognition more operationally exposed than the warehouse floor. Voice-directed picking sends an order picker to a bin with a spoken instruction, expects a verbal confirmation back, and pushes the result straight into the WMS.
Every step in that loop carries an identifier, and every identifier is a potential failure point.The error surface is wide enough that the workflow itself, more than any single recognizer setting, decides whether the system is fit for production:
Industrial noise from machinery and forklifts measurably reduces ASR performance and pushes error rates up across all of the steps above. Overlapping speech from nearby pickers compounds the problem: every additional voice in the audio is another source of transcription errors. Audio filtering, speaker diarization and representative real-world testing all matter once the recognizer leaves the demo environment. Background noise in a warehouse affects workforce adoption, not just transcripts, and customers running pick-by-voice in noisy environments need to plan for it from day one.
Custom vocabulary: the highest-leverage fix
Custom vocabulary is the single most impactful improvement most teams can make in a working day. It biases the recognizer toward terms you know matter: active product names, brand terms and model numbers, instead of generic English. Speechmatics’ Custom Dictionary supports up to 1,000 words or phrases per job and accepts sounds_like pronunciation hints for terms outside standard English phonetics.
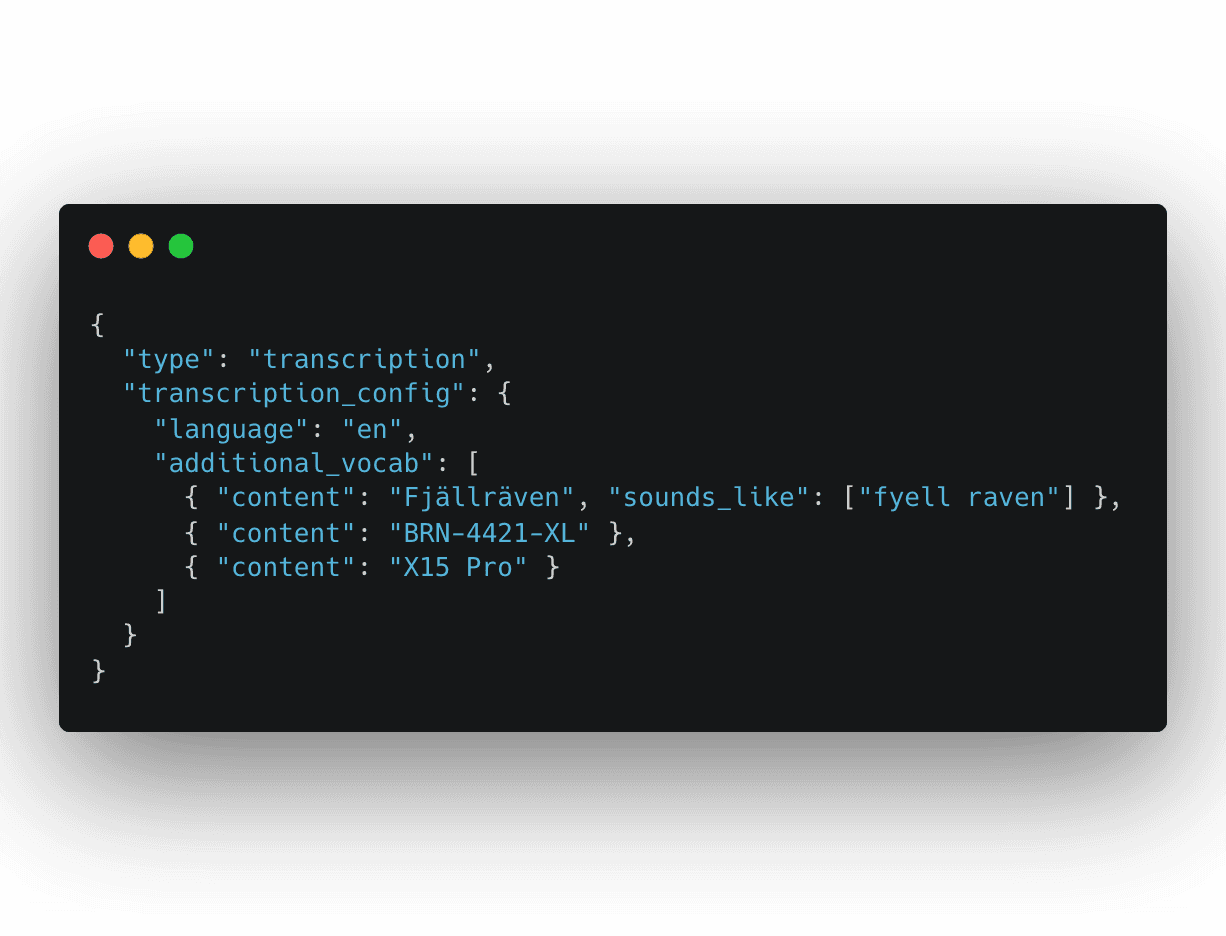
Two practical points. Focused beats comprehensive: a vocabulary of 50,000 SKUs can degrade accuracy by flooding the model with low-prior strings, while a focused list of the top 1,000 active SKUs and the most-confused brand names will reduce errors more reliably. And refresh the vocabulary as the catalog changes.Avoid special instructions that ask the model to self-correct, which introduce unpredictable behavior at exactly the moment you want determinism. For implementation detail, start with the Custom Dictionary documentation, then use the Realtime WebSocket API reference or Batch transcription quickstart, depending on your workflow.
Catalog-aware transcription and post-processing
The next layer is to constrain what the recognizer is allowed to output. If only 50 SKUs are valid in this session, bias toward those 50. If the postcode pattern is fixed, reject strings that fail the pattern. Three patterns work in production:
Constrained decoding at inference time: The W3C Speech Recognition Grammar Specification, SRGS, is the standards reference; older Microsoft Research work showed regex-derived grammars can cut semantic error rates by more than 50% on alphanumeric inputs.
Catalog-aware post-processing: Fuzzy-match the raw transcription against the active catalog, and apply a confidence policy: high-confidence near-match auto-corrects, ambiguous matches trigger confirmation, low-confidence captures return unknown.
Domain-specific NLU: Map spoken attributes, such as color, size and quantity, to the correct product record so “large navy slim-fit” resolves as a structured query. The principle: ambiguous audio plus narrow constraints beats clean audio plus open constraints. To reduce errors at scale, reduce the space the recognizer is searching, then catch what slips through with confirmation.
Speechmatics’ formatting documentation is useful here because it covers smart formatting, entity classes and how spoken numbers, dates, currencies, email addresses, web URLs, measurements and alphanumeric sequences appear in transcript output.
Confirmation design that catches errors without adding friction
Custom Dictionary and catalog-aware matching cover most of the recognition risk, but the last line of defense is interaction design. Explicit confirmation before order execution is non-negotiable for SKU-dependent workflows; done well, it catches a confident wrong answer without adding perceptible friction.Three patterns earn their keep:
For live systems, Realtime output, turn detection and ForceEndOfUtterance are especially relevant. They help teams manage when a transcript is final, how quickly a system should respond, and when a voice agent should move from listening to acting. We have this covered this in more detail in Speed you can trust: the STT metrics that matter for voice agents and You can’t hurry love, but you can hurry final transcripts.
Deployment and model selection
Use real-time transcription for live voice ordering, voice picking and conversational voice AI agents. Use batch transcription for QA, audit and historical benchmarking. Use on-prem or on-device for warehouses, distribution centers and contact centers with sensitive catalog data or limited connectivity. Multilingual support matters more than most teams plan for: the same SKU is read by Hindi-speaking, German and Portuguese callers on the same queue, and bilingual code-mixing is common. If the language model can only handle one language at a time, alphanumeric accuracy collapses on every code-switch. Speechmatics supports 56+ languages, including bilingual and multilingual speech-to-text, and offers flexible deployment across cloud, on-prem and on-device environments. For teams building production voice agents, we also support integrations with Vapi, LiveKit and Pipecat.
Measuring SKU recognition accuracy
None of the fixes above can be tuned without a scorecard, and most teams arrive at this work measuring the wrong thing. WER is the wrong thing. Speechmatics’ accuracy benchmarking documentation is the place to start, but for SKU recognition the metrics worth tracking, in priority order, are these:
For companion reading, see Speechmatics’ assessing speech-to-text accuracy guide and the breakdown of speech-to-text metrics for voice agents.
Inside the Speechmatics alphanumeric uplift
Building the scorecard above is more straightforward when the underlying ASR is already strong. Speechmatics has invested heavily in alphanumeric recognition over the past year, and the result is a step up across every category that matters for SKU capture, voice ordering, voice picking and contact-center identification: big uplifts across the board, now highly competitive on character and digit sequences. Our internal yardstick is sequence accuracy: the percentage of alphanumeric sequences that come back semantically correct, meaning the underlying sequence can be reconstructed exactly. The metric is forgiving on surface form but strict on content. Given the spoken sequence “one two double three,” we accept any of the following as a hit:
“1233”
“1.2.3.3”
“one two double three”
“one two three three”
“one two thirty-three”
That framing matches production reality. A downstream LLM, parser or catalog matcher can normalize surface form.What it cannot recover is a missing character or a substitution it never saw. On internal benchmarks the current model lands at:
On character and digit sequences the current model sits comfortably in the leading group of commercial ASR systems benchmarked on the same transcription data. On mixed alphanumerics, performance is well clear of the previous generation, and continued work on this domain is part of the active alphanumeric program.
For customers running production transcription against catalog data today, the headline is simple: alphanumeric capture is no longer the weakest link in the pipeline.
What to do next
If you are running a voice assistant, voice ordering or voice picking flow against catalog data, the work to do this quarter is straightforward:Move from word error rate to SKU-level exact match in your accuracy reporting. Build a representative test set covering your active SKUs, accent mix and real audio conditions. Stand up a focused Custom Dictionary covering the top 1,000 active product names, brand terms and model numbers. Refresh it as the catalog changes.Add catalog-aware matching with a confidence policy and audit your confirmation design. Read back product attributes for human users; use check digits for warehouse pickers. Most customers see the bulk of their wrong-ship and mis-route errors disappear inside a quarter once these layers are in place. Try the Custom Dictionary on your own audio, start with the Speechmatics developer quickstart, or test live flows with Real-Time Speech-to-Text. Make sure to tag us or reach out to us with what you're building so we can share your build with our wider community. Happy building!
Frequently asked questions
Why do voice assistants struggle with SKUs?
SKUs are arbitrary alphanumeric strings, not natural language. The language-model context that helps regular speech recognition disappears, and letter and digit names in spoken English are highly confusable. The problem is structural, not acoustic.
Why is word error rate not enough?
WER is a token-level average, and identifier capture is binary: every character has to be right or the order fails. In SNuC research, 96.6% word-level accuracy still translated to only 77% full-identifier exact match. For SKU recognition accuracy, sequence-level exact match is the only metric that maps to wrong-product outcomes.
Can a custom dictionary fix model numbers and product names?
It helps substantially for active product names, brand acronyms and proper nouns. Speechmatics’ Custom Dictionary supports up to 1,000 words per job with sounds_like hints. It works alongside catalog-aware matching and confirmation design, layered on top of each other.
How do warehouses reduce voice-picking errors?
They combine spoken instructions with location confirmation codes, quantity confirmation steps, check digits and tight WMS integration. The interaction design carries most of the accuracy load; the recognizer is one input into that design. Teams should also test against realistic noise, accents and overlapping speech using audio filtering, speaker diarization and representative production audio.
Why do regional accents and warehouse background noise matter so much?
ASR systems generalize poorly on diverse accents, and industrial noise measurably reduces both performance and user acceptance. Both effects are amplified on alphanumeric input because there is no language-model prior to fall back on. Representative test audio across accents and noise conditions is the only safe way to know how the system behaves in production. Speechmatics’ real-world accuracy positioning is built around this exact problem: speech recognition has to work across accents, noise and code-switching, not just clean benchmark audio.
Does domain adaptation actually help with spoken identifiers?
Yes. In SNuC, identifier-specific adaptation moved sentence-level accuracy from 77% to 91.7%. Speechmatics’ alphanumeric uplift confirms the same pattern at scale: targeted investment delivers 96.9% / 98.0% / 85.4% sequence accuracy on character / digit / mixed sequences.
Resources
Speechmatics Custom Dictionary documentation: request format, sounds_like syntax and per-job limits.
Speechmatics formatting documentation: entity formatting for numbers, dates, codes, email addresses, URLs and measurements.
Speechmatics accuracy benchmarking documentation: guidance for measuring model performance.
Realtime transcription quickstart: for live voice ordering, voice picking and voice agent flows.
Batch transcription quickstart: for QA, audit and historical benchmarking.
Speechmatics GitHub Academy: runnable real-time and batch examples.
Assessing speech-to-text accuracy: a sceptic’s guide: companion read on why headline accuracy numbers should be treated carefully.
The Problem with Word Error Rate: why WER can hide the errors that matter most.
Consistent transcription of numbers improves contextual understanding of conversations: deeper context on numeric formatting and understanding.
Speed you can trust: the STT metrics that matter for voice agents: companion read for live voice AI systems.
Speechmatics Voice Agent API: for builders working on production voice agents.
Speechmatics Speech-to-Text API: real-world speech recognition across 56+ languages.
Speechmatics on-device speech-to-text: for local, secure and offline-ready speech recognition.
Speechmatics contact center transcription: for customer service, agent assist and speech analytics workflows.
Speechmatics medical transcription: for clinical transcription, dosages and high-stakes healthcare speech.
Related Articles
- TechnicalMay 20, 2025
The return of on-premise: Why enterprise AI's head is no longer in the cloud
 Brad PhippsDirector, SaaS & Infrastructure
Brad PhippsDirector, SaaS & Infrastructure - ProductUpdated: Aug 31, 2025
Knowing who said what: the importance of Speaker Diarization for analytics and conversations in Voice AI
 Stuart WoodProduct Manager
Stuart WoodProduct Manager - Use CasesUpdated: Apr 19, 2026
Best speech-to-text AI guide: APIs, platforms and services compared
Tom YoungDigital Specialist
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
Product
Speaker Focus: Fixing Voice AI for the real world
Anthony PereraProduct Marketing Manager

News
Stenograph and Speechmatics Announce Industry-First On-Device Integration for CATalyst VP
SpeechmaticsEditorial Team
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
Community
From a Parked Side Project to 30 Teams Running Real Sales Calls on Speechmatics
Kyle DowFounder, Deals Machine (View1 Studio)

Use Cases
Dutch doctors spend a quarter of their day on admin. Wellcom has built the fix.
SpeechmaticsEditorial Team

General
A Practical Guide to Building Voice AI Applications With Real-Time Transcription in 2026
SpeechmaticsEditorial Team

Company
Speechmatics versus Whisper: how Adobe Premiere's on-device speech engine got rebuilt
Andrew InnesChief Architect