Blair RobertsonAccount Executive
Jan 22, 2024 | Read time 7 min
How Key IVR uses speech technology to create a seamless user experience
Building Key IVR's secure payment services - and understanding the difference between a green park and Green Park.
Paying for things? Simple. Except for when it's not.
For many, paying for things over the internet has become second nature, with autocomplete further making that process easier.
Need to buy a new pair of skis? Done in a single click ✔️
Need to pay council tax online? Easy ✔️
Want to pay for parking? There’s an app for that ✔️
However, that is simply not possible for many...
An estimated 37% of the world's population - or 2.9 billion people - have still never, ever used the internet.
The charity Age UK estimates that 40% of the over-75s in the UK don't use the internet at all and are struggling to access basic services as a result.
Between 20-29% of UK adults have reported dexterity issues, which can involve using devices like a keyboard or telephone keypad.
Accessibility challenges - overcoming barriers in online payments
For these groups using the internet to pay for goods and services or provide other information, it isn't simple at all.
Many of these people have to find alternate ways to provide this information, with one such way being over the phone.
Navigating internet payment hurdles
There are instances where it's more suitable to speak to someone over the phone before a payment is made. For example, when booking a medical appointment, agreeing on details of an insurance policy, finalizing plans for a holiday, or negotiating a payment arrangement for repaying outstanding debt.

Whether it's speaking to a contact center agent or an automated phone system, payment card details must somehow be provided by the customer. Ideally, no one wants to be reading any sensitive details to someone over the phone.
This is often done using the numeric keypad of a phone using something called Dual-tone multi-frequency (DTMF) technology. This works by having the handset generate tones at specific frequencies and playing them over the phone line when a button is pressed on the keypad. Equipment at the other end of the phone line listens to the specific sounds and decodes them.
In the case of payments, customers enter their card number, expiry date, and CVV code (the one on the back of the signature strip) and the information is passed on for processing.
It's a method that has been used for decades but can have significant limitations for some people. For one, it can be fiddly on phones with small numeric keypads. It can be easy to mistype on a touchscreen smartphone device, and it is also impossible to correct mistakes without waiting for the system to tell you.
So, if you want to make it easy for as many people as possible to have the ability to provide their payment details, even at times when regular call centers may be closed for the day, how should you do this? How can you make your service as inclusive as possible?
This is a challenge that Key IVR has taken on.
Security, compliance, and innovation - Key IVR's approach to payment solutions
Key IVR is a privately owned business offering card payment and bank payment services to organizations across the world. Available in 14 languages across 11 currencies, they process over £1.7 billion in payments ($2.2bn) every year, all done using a state-of-the-art and secure payment suite.

For Key IVR, they have good reasons to make their offering as flexible as possible. The first is that they pride themselves on offering a bespoke approach for every single customer and operate across a wide range of industries, including charities, housing associations, and utility companies, including contact centers for many others. This makes their end users varied too, with a range of dialects, languages, accents, and accessibility requirements.
Accuracy without context - vital but hard
For Key IVR, the key question is this...
What's the easiest way for that customer to go through the payment journey in a way that's not painful?
For them, the answer to this, of course, depends on the customer, but given the drawbacks of the approaches mentioned above, Key IVR has added an additional string to their bow... Automatic Speech Recognition.
Key IVR and Speechmatics join forces
Automatic Speech Recognition (ASR), as its name suggests, allows people to talk to a computer that transcribes their words. Key IVR has integrated Speechmatics' ASR into their offering, which means that two of their main services, over-the-phone payments with an agent and payments with an automated Interactive Voice Response (IVR), can offer an alternative to asking the customer to enter secure card details on their telephone keypad.
Customers are prompted when to speak and the system listens and analyzes their audio, avoiding a lot of hurdles some may face when entering a lot of information by a numeric telephone keypad.
For customers with limited mobility that can be significantly quicker and less frustrating than entering into the keypad.
The information can be provided in several different formats or fed directly to back-office systems. This saves hours of manually transcribing details from call recordings and avoids any human error.
Compliance with industry standards
Not surprisingly, security is a primary concern for Key IVR. Any solution to this challenge must be deployed on-premise within their secure payment environment. This ruled out a couple of the bigger, cloud-based providers for Key IVR, as algorithms couldn't be copied and programmed to run within its servers. Due to the sensitive nature of the data captured and processed, it would raise issues with how their services operate.
Key IVR also ensures that any sensitive card details that are read out by the customer stay secure and aren't heard by an agent or any call recording software.
All this is essential, as it keeps the solution compliant with PCI-DSS, the industry standard in card payment technology.
A lot to consider, with plenty of challenges to overcome. So, what underpins all of these processes, and ensures they work effectively?
Partnership for progress
In the world of ASR, vast amounts of transcribed data are used to train models that, in turn, are used to transcribe audio input with as much accuracy as possible. Often, these models do a 'first pass' on a transcription before amending words based on context once the entire sentence has been finished by the speaker.
For example, an initial transcript might read:
"I would love to visit green park.... in London... one day"
Once the sentence has been entirely transcribed, further context can be derived – Green Park is not simply a park that is green in London, it is a place, so this might be amended to:
"I would love to visit Green Park in London one day"
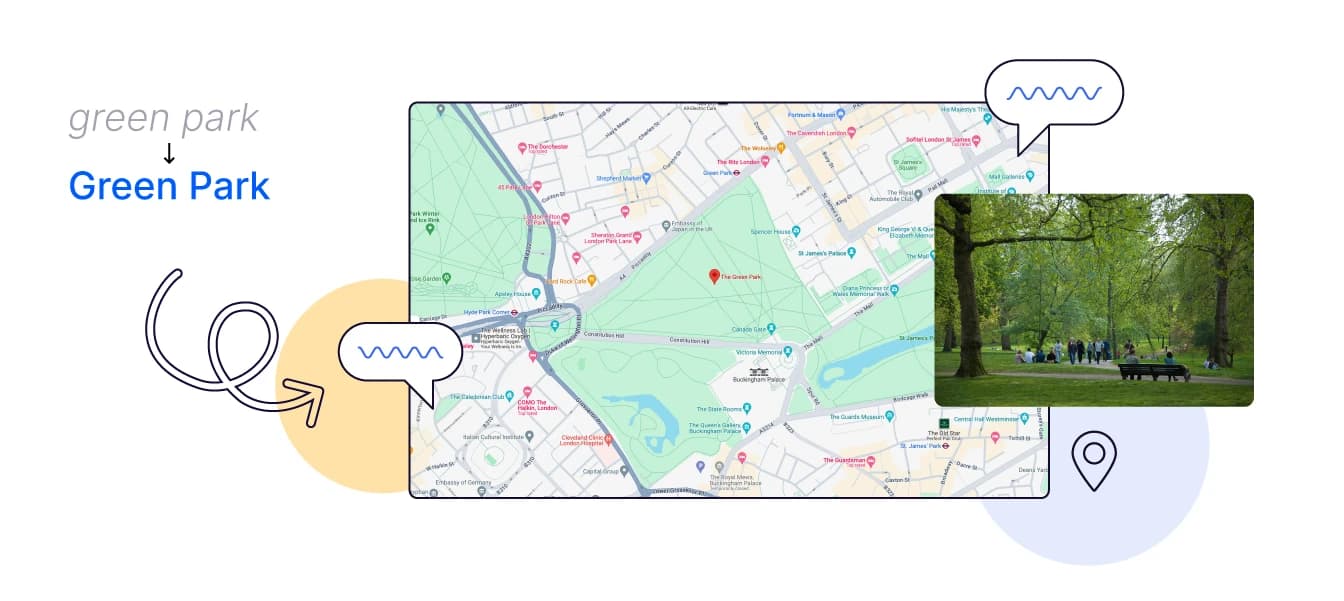
The benefits of this are clear and extremely helpful. But in our scenario here, this kind of context is unavailable.
"Nine, four, two, seven..."
If a person is asked for their credit card number, postcode, or vehicle registration number, they will simply list letters and numbers, without any additional information provided to the speech recognition software to help improve the results.
Recognizing individual letters and numbers is a hard challenge, and that's before you consider the amount of background noise and variance of accents and dialects that Key IVR might be dealing with.
To solve this challenge, they didn't just need software, they needed a partner.
Working with Speechmatics 🤝
The good news for Key IVR is that Speechmatics' accuracy with numbers and individual letters was already at a sufficient level to go straight into production. But Key IVR, like Speechmatics, is always looking to push the boundaries of accuracy and quality and began to form a close partnership in finding improvements in the ASR provided.

Choosing collaboration over giants
Collaboration was another important reason Key IVR chose not to go with a Silicon Valley giant. "We knew, given the complexity of our challenges, that we were always going to struggle to work with larger providers of this technology", says Darren Wooding, Managing Director at Key IVR.
"Because we develop our services and configure things very carefully to suit each client, in situations where the accuracy just wasn't there, we would have no way to work alongside their teams. It could be as simple as providing feedback and working with them on finding new ways to improve."
"That's why we've enjoyed working together with Speechmatics for this project – not only do they have a great team, but they work alongside us as they develop the accuracy of character recognition. They share our commitment to making ASR as accessible and inclusive as possible, and we're excited to continue strengthening our offering to our customers using Speechmatics' technology."
The team at Speechmatics loves difficult technical challenges, and working with Key IVR has given us a great opportunity to work with a customer on some of the trickier ASR challenges, all whilst improving the availability for inclusivity of goods and services.
After all, it's not just the internet that should be simple ✔️
Related Articles
- TechnicalMay 9, 2023
Best-in-class real-time ASR system
 Steve KingsleyData Engineer
Steve KingsleyData Engineer - TechnicalDec 20, 2023
Understanding Persian - bringing a new language to Speechmatics
 Liam SteadmanAccuracy Team Lead
Liam SteadmanAccuracy Team Lead - ProductOct 17, 2023
Foundational speech technology for the AI era - Speech Intelligence is here
 Katy WigdahlCEO
Katy WigdahlCEO

Use Cases
Dutch doctors spend a quarter of their day on admin. Wellcom has built the fix.
SpeechmaticsEditorial Team

Company
Speechmatics versus Whisper: how Adobe Premiere's on-device speech engine got rebuilt
Andrew InnesChief Architect

General
A Practical Guide to Building Voice AI Applications With Real-Time Transcription in 2026
SpeechmaticsEditorial Team

General
How to Add Automatic Captions to Media Content Using a Speech-to-Text API
SpeechmaticsEditorial Team

General
How Modern Law Firms Can Use AI Transcription Without Compromising Client Data
SpeechmaticsEditorial Team

General
The Complete Guide to AI Medical Transcription for Clinical Workflows in 2026
SpeechmaticsEditorial Team