
Benedetta CevoliSenior Machine Learning Engineer

In 2003, the UK government banned the use of hand-held mobile phones and other hand-held devices while driving a vehicle. In March 2022, they went a step further, banning drivers from taking photos or videos, and even scrolling through playlists or playing games. To use your phone, you need to be stationary with the keys removed from the ignition. Either that or an accurate speech-to-text system.
In our increasingly plugged-in society, dangerous distractions are available at your fingertips. 1 in every 4 car accidents in the US is caused by texting and driving, so, to avoid increased accidents, manufacturers are adapting to the times by using the latest speech-to-text technology in their vehicles.
Accurate voice recognition is necessary in any modern vehicle. A competent system should enable the driver to change a song, find a route/destination, set a service appointment, send emails/messages, and even set calendar appointments. In the future, we might be using our voice to direct self-driving cars, for example, by simply saying “drive me to London Paddington”.
Car environments are notoriously noisy. The level of noisiness can vary drastically depending on a multitude of driving conditions, such as the vehicle speed, road surface, engine revs as well as atmospheric conditions such as wind and rain. Such noisy environments are a perfect test for our aim to understand every voice in every situation. That’s why we set out to learn how our Autonomous Speech Recognition (ASR) fares while being used in vehicles.
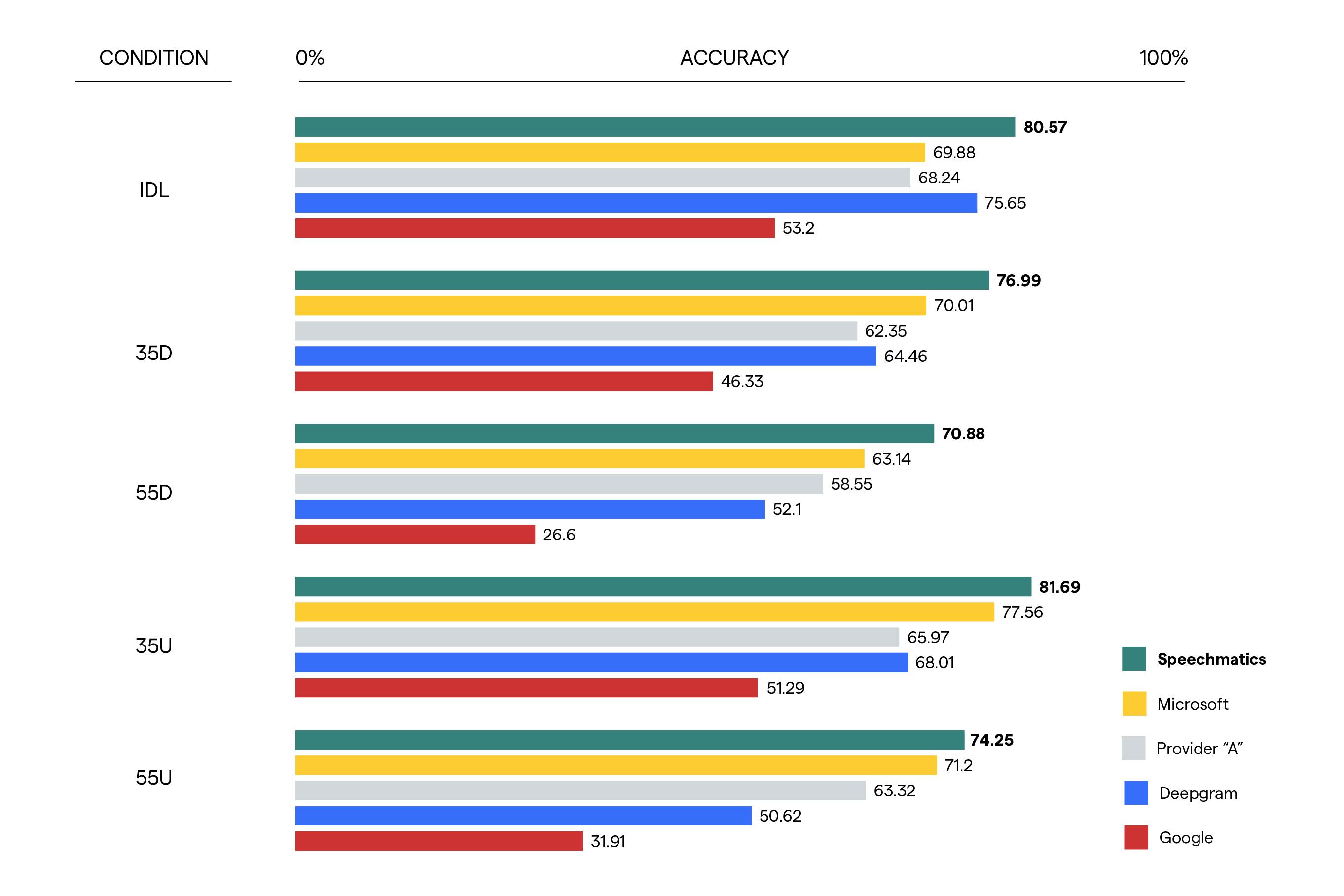
To do so, we used the Audio-Visual Speech Recognition in a Car (AVICAR) corpus which includes different types of speech from 86 English speakers in-car environments with varying noise conditions: engine idling (IDL), 35mph with the windows up (35U), 35mph with the windows down (35D), 55mph with the windows up (55U), 55mph with the windows down (55D).
Using these five conditions, we tested accuracy levels based on weighted average word error rate (WER) against our competitors and found that Speechmatics’ ASR is incredibly more accurate in vehicles compared to some of the industry’s biggest names, with a difference in errors from 60% to 22% from the least accurate to the second most accurate provider.
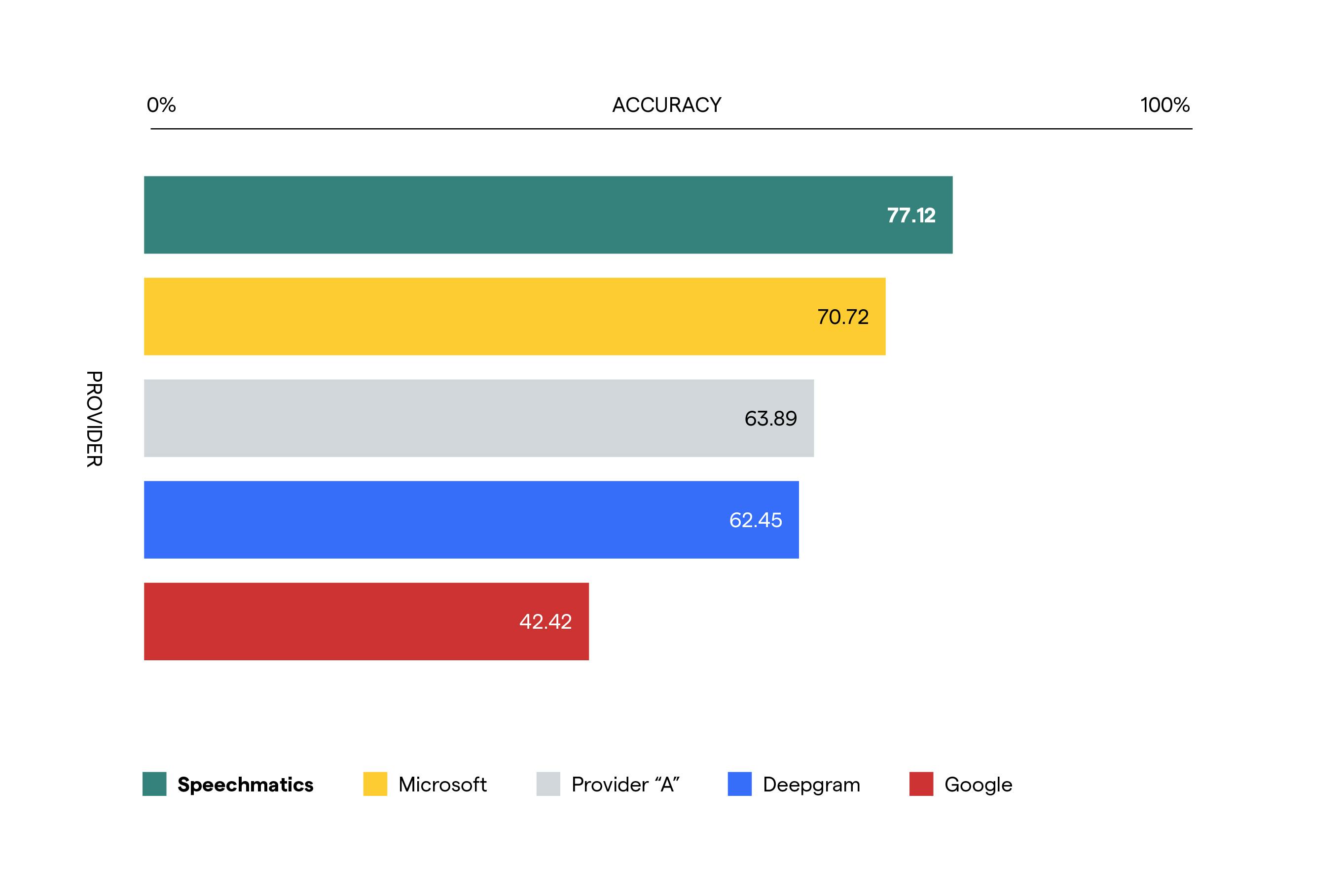
This pattern is consistent across the five noise conditions: Speechmatics is the most accurate in every single condition. Critically, the data also shows that the absolute difference in accuracy between Speechmatics and the other closest provider doubles in conditions with the highest level of noise (the highest speed with windows down, 55D: 8% difference in accuracy) compared to the one with the lowest level of noise (the lowest speed with windows up, 35U: 4% difference in accuracy). This means that as the level of noise increases, the largest is the difference in accuracy between Speechmatics and competitors.
![[alt: Medical model header asset]](https://images.ctfassets.net/yze1aysi0225/5MipUIKLJqAwbaIXNQeua8/9ea3ae3a2c022b72abbf56e26579393f/Medical_model-Header_4x3.svg)
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)

![[alt: Pattern of blue coins with "Cr", circuit symbols, and sparkles on a dark teal background, creating a crypto-themed design.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F5wtHENHGzT1GK6tG4M6USf%2Fa380442e95ea4f30ad0f5e6c42ea7ee8%2Fpricing-change-wide-carousel_2x_1.webp&w=3840&q=75)
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
