
Benedetta CevoliSenior Machine Learning Engineer

At Speechmatics, we're constantly working to grow our Autonomous Speech Recognition (ASR) capabilities. We've mastered 33 languages, but the research doesn't stop there. To understand language in a more comprehensive, authentic way, we must look at the role of emotion in speech-to-text.
Speech is a naturally rich tapestry of ever-changing emotions. It's a crucial part of human communication, so the boundaries of emotion in speech-to-text will always push. Naturally, we tested our ASR on the beloved TV show Friends' character's voices.
Set in 90's New York, the iconic sitcom follows Ross, Rachel, Monica, Chandler, Phoebe, and Joey through the trials and tribulations of adulthood. The show's rich storytelling ensures a vast array of emotions throughout the seasons, making it the perfect subject for our test.
To analyze the accuracy of our ASR, we used the MELD dataset, which includes 1400 dialogues and 13000 utterances from the show, accompanied by emotion and sentiment annotations. We calculated transcription accuracy for each utterance using Word Error Rate. We then measured ASR's accuracy levels for each character's emotions: fear, neutral, anger, disgust, joy, positive, and negative surprise.
Amongst the different emotions, fear stands out the most. Compared to 85% neutral accuracy, fear registered an average of 78% - a 7% absolute difference.
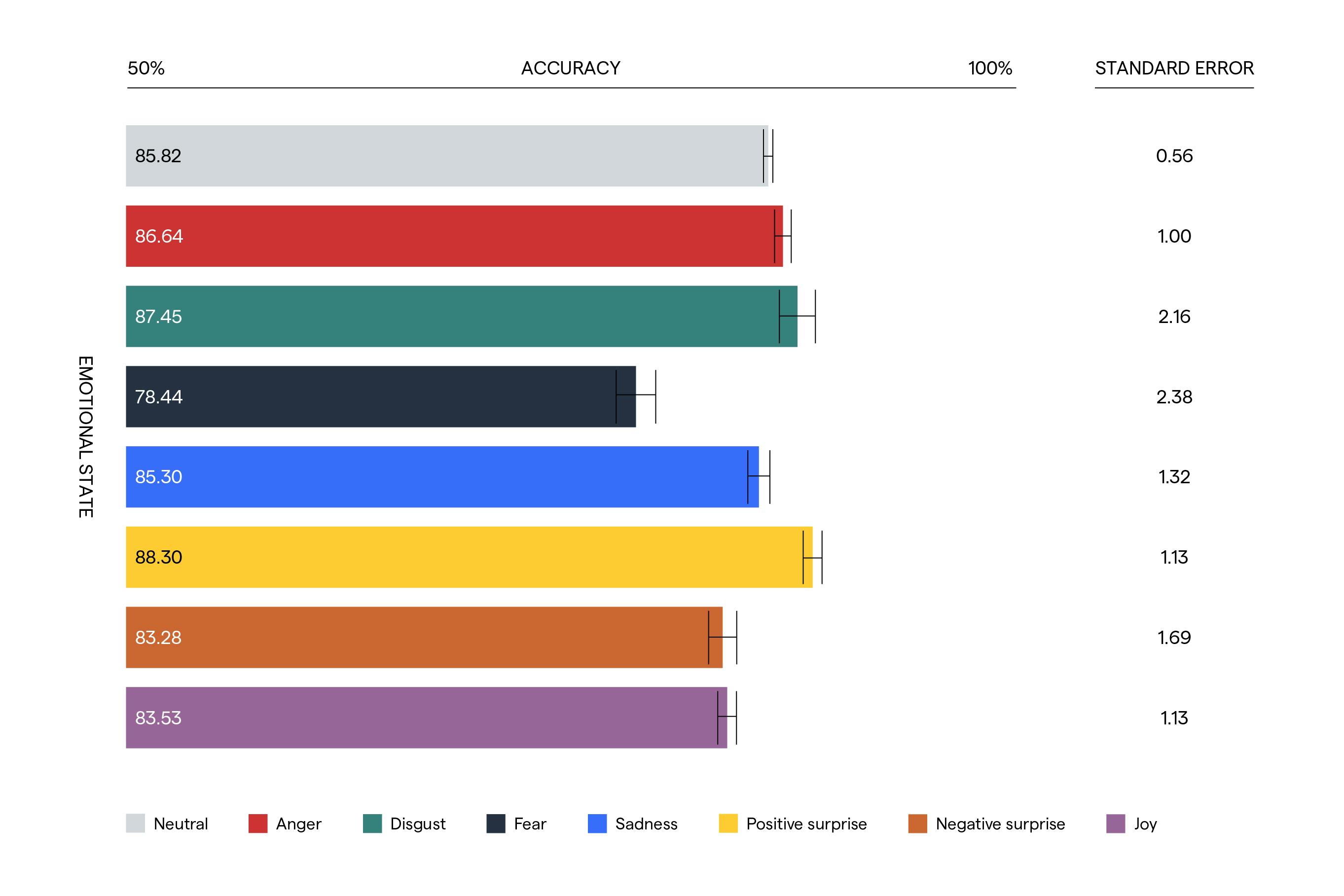
Even if accuracy varies across the other emotional states, none of these differences is statistically significant. You can see in the figure above that the error bars are overlapping, which means that these minor differences are likely due to chance, and in reality, transcription accuracy for neutral and anger, for example, are comparable. But if we take a closer look, we can see the pattern of results changes.
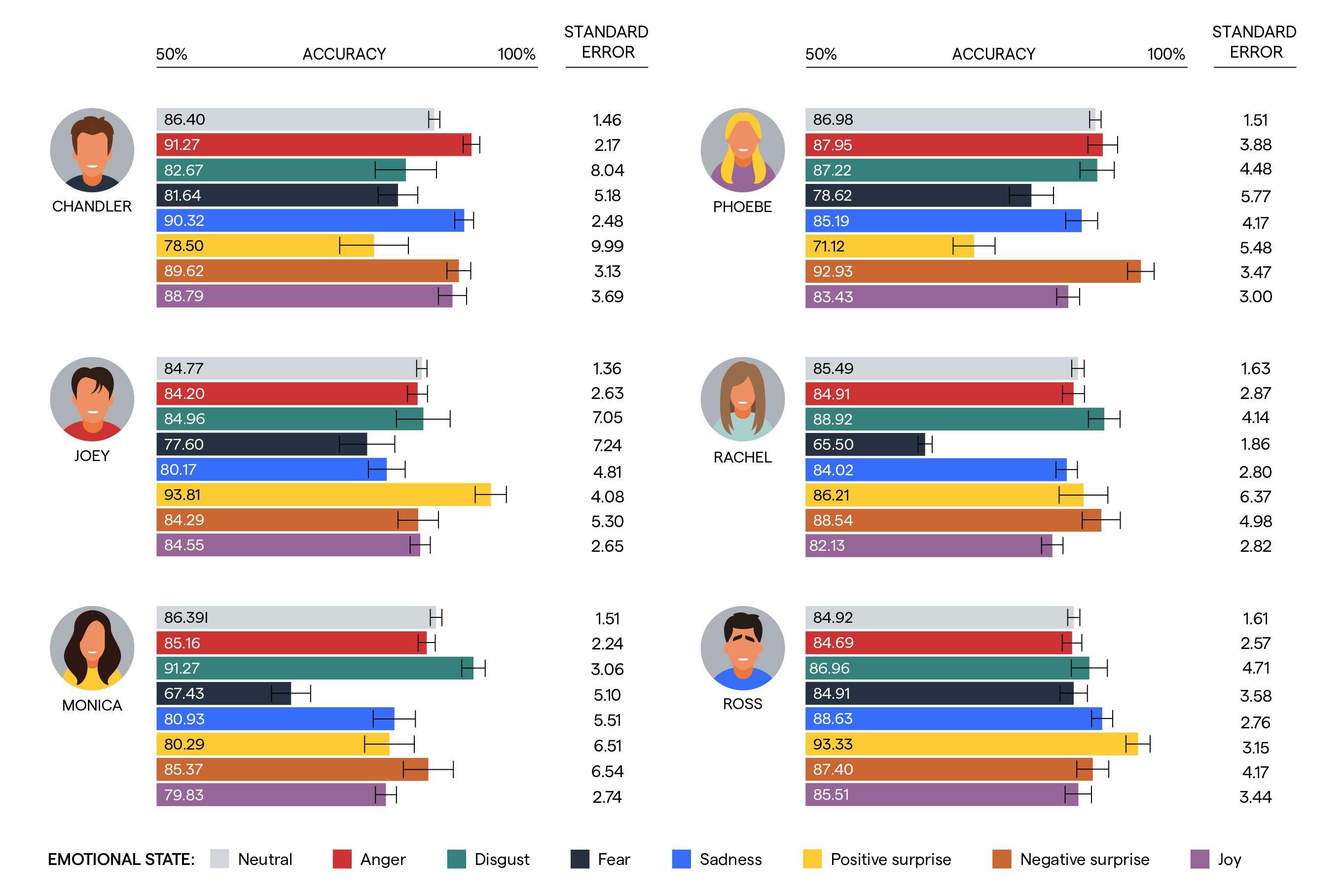
Monica and Rachel's accuracy drops to 67% and 65% for fear, but not for the rest. Phoebe, Ross, Chandler, and Joey all have a fear accuracy comparable to neutral accuracy. Again, even if these slightly vary, none of the differences is statistically significant – it's probably just chance. But Rachel and Monica's fear accuracy is statistically different to neutral accuracy.

![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)


