
Stuart WoodProduct Manager
In critical professional contexts, accurate communication is non-negotiable. Whether documenting important findings, recording conversations, or creating accessible content, the fidelity between spoken and written language can make all the difference — especially in linguistically complex regions like Norway.
That's why our recent achievement resonates far beyond mere technical metrics: we've eliminated 40% of transcription errors in Norwegian speech recognition, representing 1,400 fewer mistakes per hour of audio.
While we recently built Persian from scratch in just 4 weeks, continuously improving our roster of 50 languages remains equally essential.
For Norwegian, with its distinctive dialects and dual written forms, we developed specialized techniques that dramatically improved transcription accuracy.
In this blog, we'll explore the unique challenges of Norwegian speech recognition and how we overcame them.
Even proficient linguists can find themselves in a tight spot when faced with regional dialects or specialized jargon.
Imagine navigating through the nuances of a physics lecture in another language or adapting to the linguistic differences of a new geographic region that speaks seemingly the same language.
These same variations make it a challenge for AI to understand what people are saying.
Common challenges include:
Acoustic Variations How words are pronounced can vary dramatically depending on the speaker's origin and how fast they speak. Take, for instance, the simple example of “router,” which is pronounced “rau·tr” in American and “roo·tuh” in British English. Speech recognition needs to handle these differences to consistently transcribe the correct word.
Diverse Vocabulary The context of a conversation greatly influences the vocabulary used. A medical discussion employs a different lexicon than sports commentary. Even within the same language, regional variations exist – in English, it could be a “lift” or an “elevator”. Speech recognition needs to understand every word spoken in a language, including unusual synonyms, and adapt as new words enter our vernacular.
Grammatical Intricacies Languages often present additional grammatical challenges. An example for Norwegian is compound words – combinations of two or more words to create a single term. These linguistic features demand sophisticated language understanding from AI to present a readable transcript. Read more about compound words in Norwegian.
Norway. Part of the Nordic region in Northern Europe. Famous for Vikings, beautiful Fjords, and the Northern Lights.

It has 5.3 million speakers worldwide (vs. 1.4 billion English) with a rich tapestry of linguistic nuances, which presents a set of challenges for speech recognition technology. Even some native speakers may not be fully cognizant of the subtle complexities inherent in their language.
We will look at the challenges for a robust Norwegian speech-to-text solution and how we address these.
Two of the key factors:
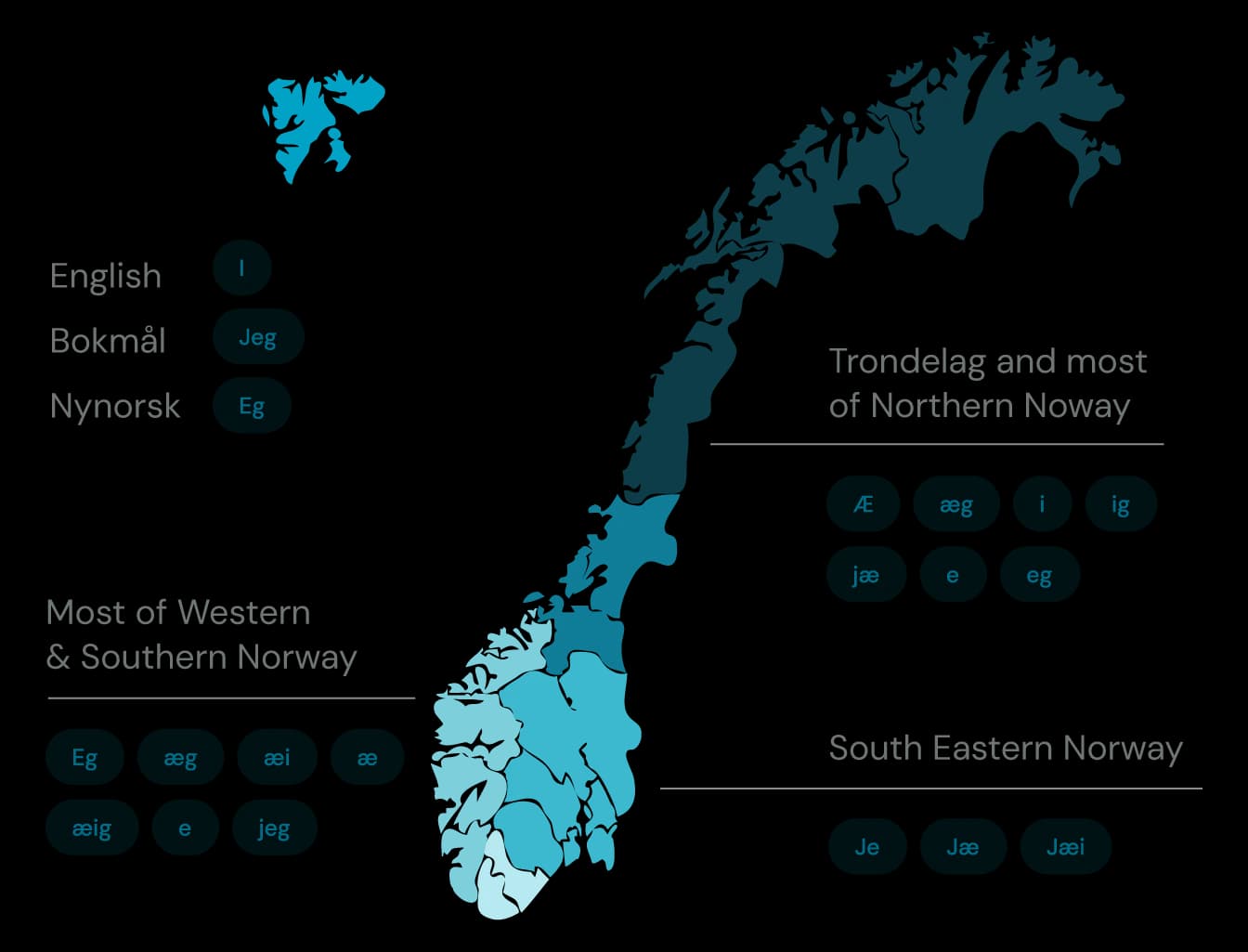
1) Diverse Dialects Across Five Regions The Norwegian spoken language is a mosaic of dialects, primarily categorized into five geographic regions: North, East, South, West, and Trøndelag. Each region boasts its own dialectal idiosyncrasies, making it a challenge for foreigners and sometimes even locals to understand variations from neighboring towns.
2) Dual Written Forms, Bokmål and Nynorsk Norway has two officially recognized writing systems, Bokmål and Nynorsk. These are not just dialects, but distinct written standards, each with its own grammatical norms and vocabulary.
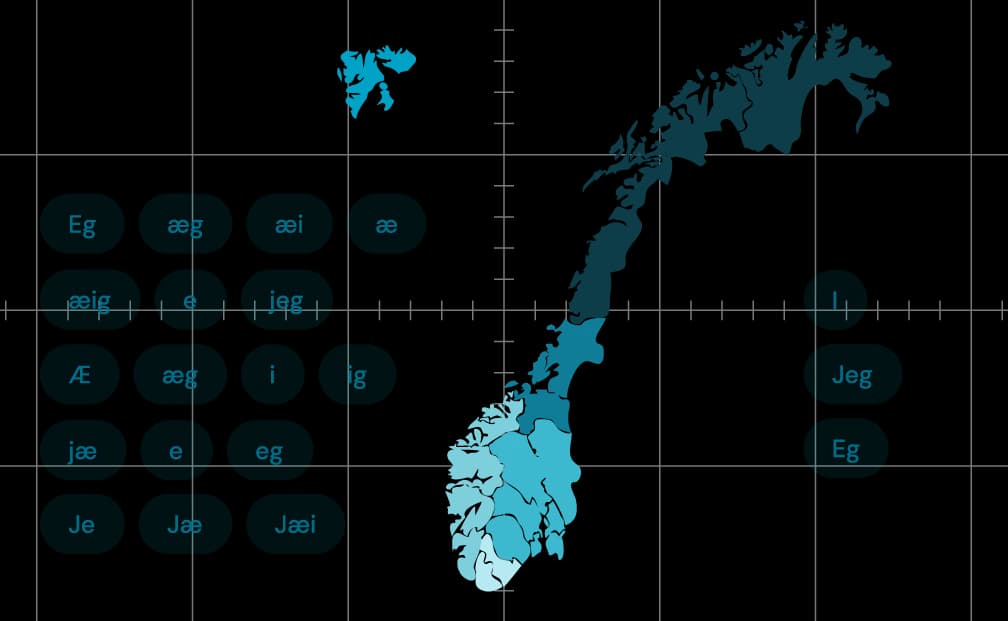
Here is a quick example of how the pronunciation of the word “I” changes between regions:
(Credit to this Norwegian language channel on YouTube)
To illustrate the diversity within Norwegian dialects further, this video provides a tour of the 19 different regional variations.
This example provides a glimpse into Norway's wide variety of accents and speech patterns.
So, how do we tackle the accuracy challenges?
We have 3 main levers to help our speech recognition improve:
1) Model Improvements Making better use of existing data through better machine learning techniques.
2) Better Data Adding more audio from a diverse pool of speakers or increasing the diversity of our text data.
3) Language-Specific Improvements Identifying and improving specific linguistic issues, for example, compound words in Norwegian.
Let's look at each area in turn, and how they can help.
Improving our models' architectures can significantly improve accuracy across many languages simultaneously. However, it also takes the highest effort from a team of dedicated machine learning engineers.
An example, recently, we grew the size of our models (increasing the parameter count, allowing them to learn more information), which has had a widespread and large positive impact on accuracy for multiple languages.
It gave up to a 25% reduction in errors across our languages. You can read more about it on our Ursa blog.
With the latest developments in our self-supervised models, model training requires fewer hours of labelled data (audio with a corresponding perfect transcript) to get high accuracy on different dialects, so variety rather than quantity is key.
To increase the variety of dialects within our training, we worked collaboratively with Sikt, the University in Oslo and several other universities in Norway, to collect region-specific training data with speakers from across Norway.
"Speechmatics invested heavily to ensure they could understand the accents, dialects, and nuances of the Norwegian language.
Better Norwegian speech to text is important for the learning experience for our students and to save time for educators working with captions. Good support for Norwegian is also important to our linguistic identity - working with Speechmatics has been essential to make the project possible and to achieving improvements which will benefit our users and other Norwegian speakers.”
Oddmund Møgedal, University of Oslo
As part of the project, we also collected specific test data for each region to understand where our efforts are best spent.
We also relied on open-source data collection projects to bolster the training data for our models. For example, we added audio recordings of meetings in Stortinget (Norwegian Parliament) and data collected by Nordic Language Technology.
There are multiple language-specific ways to improve; for example, how numbers are formatted in a language can differ.
Punctuation can differ from one language to the next, whilst a full stop in English is ".", in Hindi it’s "|", and in Chinese/Japanese they use the wide space character "。".
These differences require careful attention to get right for a readable transcript.
For Norwegian, one of these challenges is the use of compound words.
Compound words are when two or more words are combined to make new words, often with a new, but related meaning. They are common in many languages, including English – although in English they’re less prevalent, for example “bedroom”. In Norwegian, it’s possible to link together as many as 4 words into one.
Supporting all these combinations would require a large list of words stored in the models. Instead, we allow our models to learn when it makes sense to combine words to be compound and when it makes sense to keep them separate. This means that as new words emerge from combinations of existing words, we can have a chance to transcribe them even though it’s never seen the word before.
A simple example:
norsklærer - Norwegian teacher
This is made from:
norsk – Norwegian
en lærer - a teacher (“en” dropped)
A longer example:
Menneskerettighetserklæring – declaration of Human Rights
This is made from:
Erklæring – Declaration
Av – of (dropped)
Menneske – human
Rettigheter – rights
We train the language model using a "subwords" technique to understand compound words. During training, we establish the list of word parts required to reproduce the vocabulary in our training data and then teach it how it can combine these parts into valid, most likely words using probabilities of what will appear next.
This allows us to recreate the long words spoken in Norwegian and adapt with the language as new words like “koronasyk” (sick from Corona) are created, even though our model may never have seen this word before.
By taking the steps above, we have been able to make a big accuracy leap for Norwegian. Overall, we reduced the number of errors by 40%, which means that for every hour of speech, we make 1,400 fewer mistakes. That enables better readability of automatically generated transcripts and halves the time required for a human to proof the transcript.
Below you can see the accuracy improvements made for each of the regions. From our evaluation, there are great improvements across the board but still further we can go.
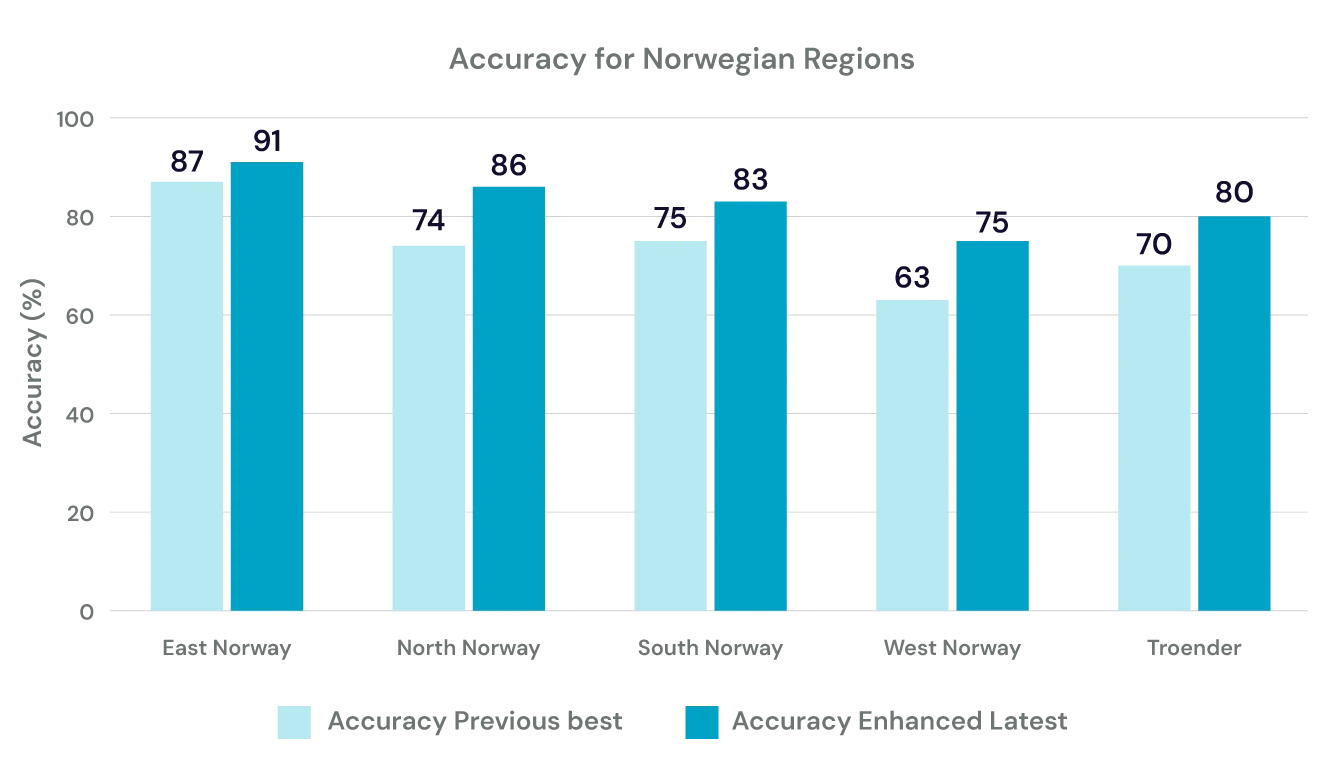
When combined with the dialect recognition improvements, Speechmatics now provides one of the most accurate Norwegian speech recognition systems available.
Our customers are already seeing the benefit of our Norwegian improvements, and our translation and Speech Intelligence capabilities benefit significantly too. When transcription is accurate, downstream tasks such as summarization and translation, which depend on accurately transcribed words, get an accuracy boost.
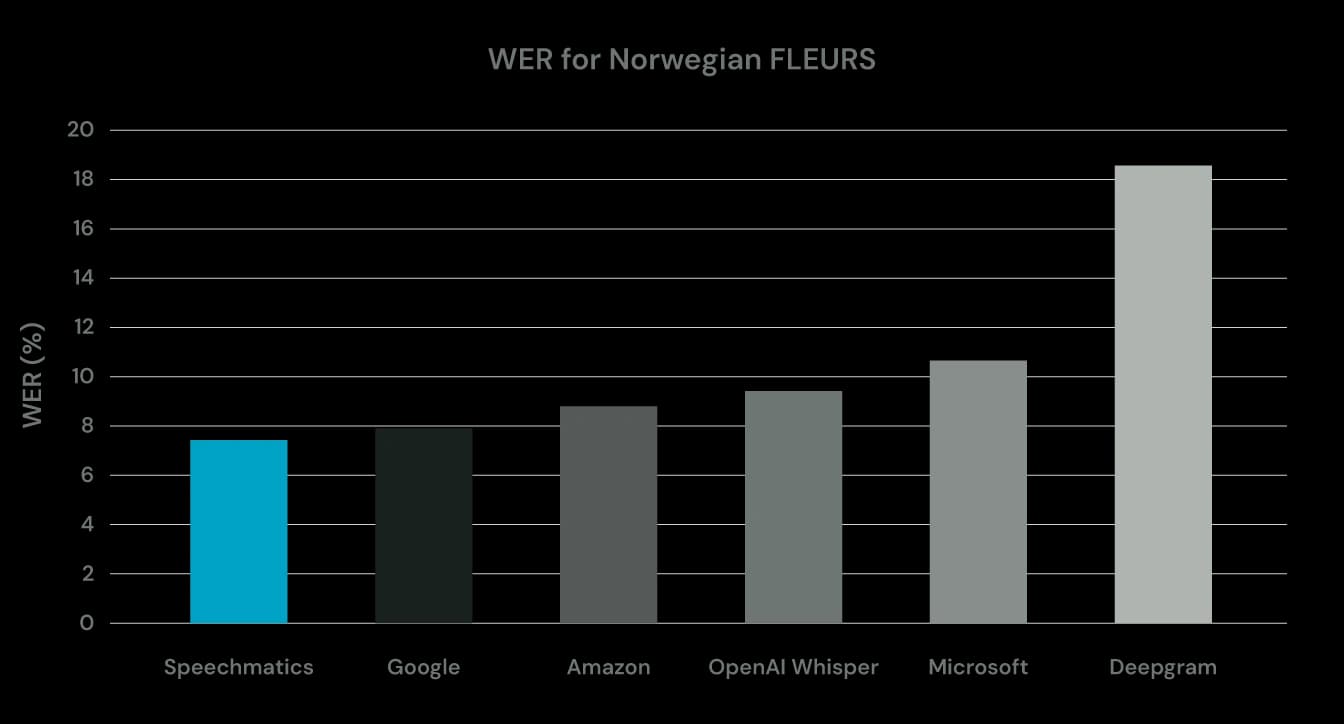
The above graph shows the Word Error Rate (WER) for the Norwegian FLEURS open dataset across key ASR providers.
This example of what we achieved with Norwegian gives you a better understanding of how our team of expert engineers work to improve accuracy across our languages. Getting this right takes machine learning excellence, quality data, and language expertise.
Follow Speechmatics as we continue the journey towards enabling machines to seamlessly understand every voice.



![[alt: Medical model header asset]](https://images.ctfassets.net/yze1aysi0225/5MipUIKLJqAwbaIXNQeua8/9ea3ae3a2c022b72abbf56e26579393f/Medical_model-Header_4x3.svg)
![[alt: Speaker lock blog image]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2Fue7vVoLyWYL8hohG7JNz6%2F0df9783d84d0e93b5b04f8ecbe33d8f0%2FSpeaker_lock-blog-v1_-_Header_16-9.webp&w=3840&q=75)

![[alt: Pattern of blue coins with "Cr", circuit symbols, and sparkles on a dark teal background, creating a crypto-themed design.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F5wtHENHGzT1GK6tG4M6USf%2Fa380442e95ea4f30ad0f5e6c42ea7ee8%2Fpricing-change-wide-carousel_2x_1.webp&w=3840&q=75)
![[alt: Phone icon with "Live" label and stacked progress bars in dark green, orange, and blue on a dark background.]](https://images.ctfassets.net/yze1aysi0225/5p7No6vDvsDDGQaWAzE494/10a4e4eb5c0579a729bbcc524d467cd9/deals-machine-wide-carousel_1.svg)
